このセクションの他の記事
- 学習とは
- AIの学習設定
- 学習の詳細設定
- 学習の実行と進捗・学習の中止
- AIの学習の終了
- 概要
- 期待される効果
- 精度評価
- 精度評価の値について
- 精度評価の見方(分類・回帰)
- 精度評価の見方(文書データ(自然言語処理))
- 精度評価の見方(画像データ(ディープラーニング))
- 精度評価の見方(時系列解析)
- テスト結果の見方(数値)
- テスト結果の見方(ファインチューニング)
- 重要度
- RAGプロンプト管理機能
- テキストマイニング
- クラスタリング
- 学習情報
- 最適化の条件設定
- 最適化の式での条件設定
- 最適化結果の見方
- 最適化の仕組み
- 他のAIを確認する
- 再学習
- 学習済みAIの保存
- AIの作成お疲れさまでした!
テキストマイニング
単語や文章など日常的に使っている言葉(「自然言語」と言います)で書かれている文書データを分析し、有益な情報を取り出すことを総称して[テキストマイニング]と言います。文書データの分析は、文章を品詞単位の単語に分け(「分かち書き」と言います)、それらの出現頻度や相関関係を数値化して行います。
[テキストマイニング]画面は、レシピに[頻度表示]ブロックや[ワードクラウド表示]ブロックを組み込んでいると表示されます。
本画面では、データセット内の単語の傾向をつかむのが目的なため、数値化の手法によって表示される内容が変わることはありません。
<参考>
数値化する手法はさまざまありますが、MatrixFlowでは次の手法を使ったレシピを作成することができます。
・Word2Vec
・BERTベクトル化
・tf-idf
・Okapi BM25+
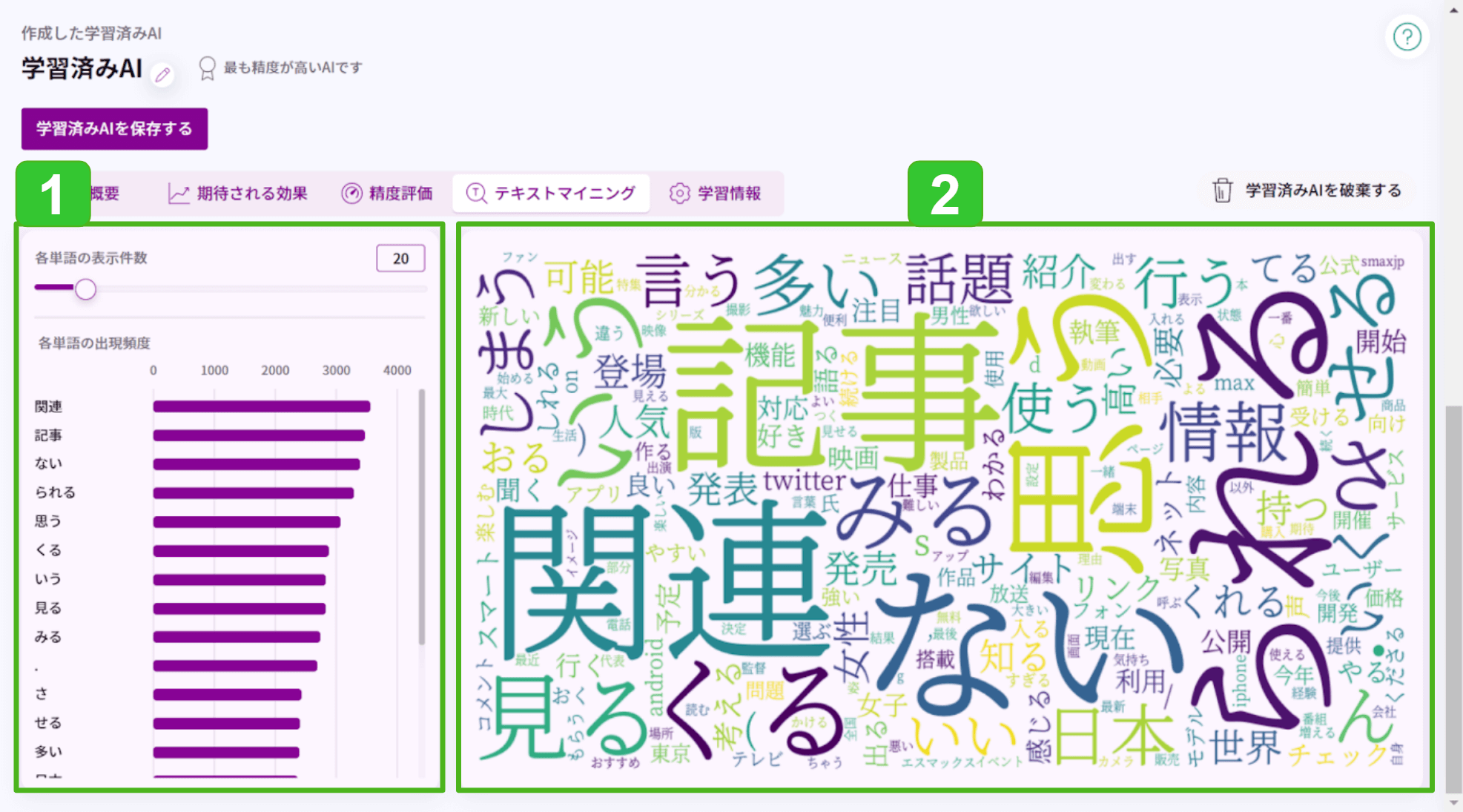
- 各単語の表示件数と出現頻度
レシピに[頻度表示]ブロックを配置していると表示されます。
表示件数:出現頻度グラフに表示する単語数を半角数字(1~200)で指定します。
出現頻度:分かち書きしたあとの単語が、データセット内で何回出現していたかカウントした値です。多い順に並べ替えて表示します。 - ワードクラウド
レシピに[ワードクラウド]ブロックを配置していると表示されます。
単語を出現頻度に応じた大きさで図示して視覚化します。出現頻度が多い単語ほど大きく表示されます。