このセクションの他の記事
- 学習とは
- AIの学習設定
- 学習の詳細設定
- 学習の実行と進捗・学習の中止
- AIの学習の終了
- 概要
- 期待される効果
- 精度評価
- 精度評価の値について
- 精度評価の見方(分類・回帰)
- 精度評価の見方(文書データ(自然言語処理))
- 精度評価の見方(画像データ(ディープラーニング))
- 精度評価の見方(時系列解析)
- テスト結果の見方(数値)
- テスト結果の見方(ファインチューニング)
- 重要度
- RAGプロンプト管理機能
- テキストマイニング
- クラスタリング
- 学習情報
- 最適化の条件設定
- 最適化の式での条件設定
- 最適化結果の見方
- 最適化の仕組み
- 他のAIを確認する
- 再学習
- 学習済みAIの保存
- AIの作成お疲れさまでした!
学習の詳細設定
学習の詳細設定は、学習の進め方に関する設定が行えます。
ただし、AIの知識をお持ちの上級者向けの設定項目ですので、まずはデフォルト設定で学習を行い、思うように精度が上がらないときに見直しを行う進め方で差し支えありません。
投入するデータセットの種類によって、設定できる項目が異なります。
■設定項目
学習グラフ表示エリアの右上[⚙学習の詳細設定]から、設定画面を開きます。

<CSV形式の表形式データセット>と
<文書データセット>
テストデータ比率:0.1(デフォルト)
学習用データセットを訓練用データとテストデータの2つに分ける際のテストデータの比率を指定します。
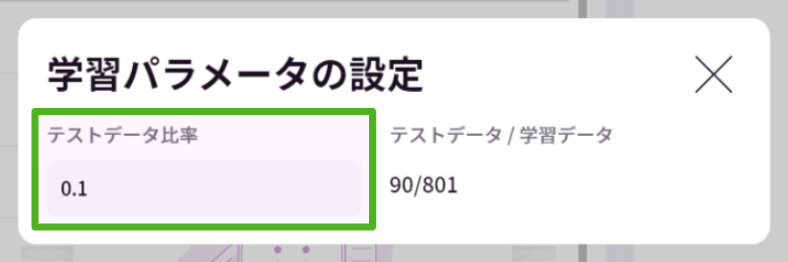
デフォルト値 0.1 の場合、投入した学習用データセットの10%分のデータ数をテストデータとして分割します。
テストデータは学習には使わず、学習の最後にAIモデルの精度を確かめるために使います。(参考:精度評価の値について)
<補足>時系列解析[MfTransformer]ブロックを利用する場合
レシピブロックのパラメータでも「テストデータの割合」を指定できます。両方に指定した場合、レシピブロックの指定が優先されます。
<画像データセット>
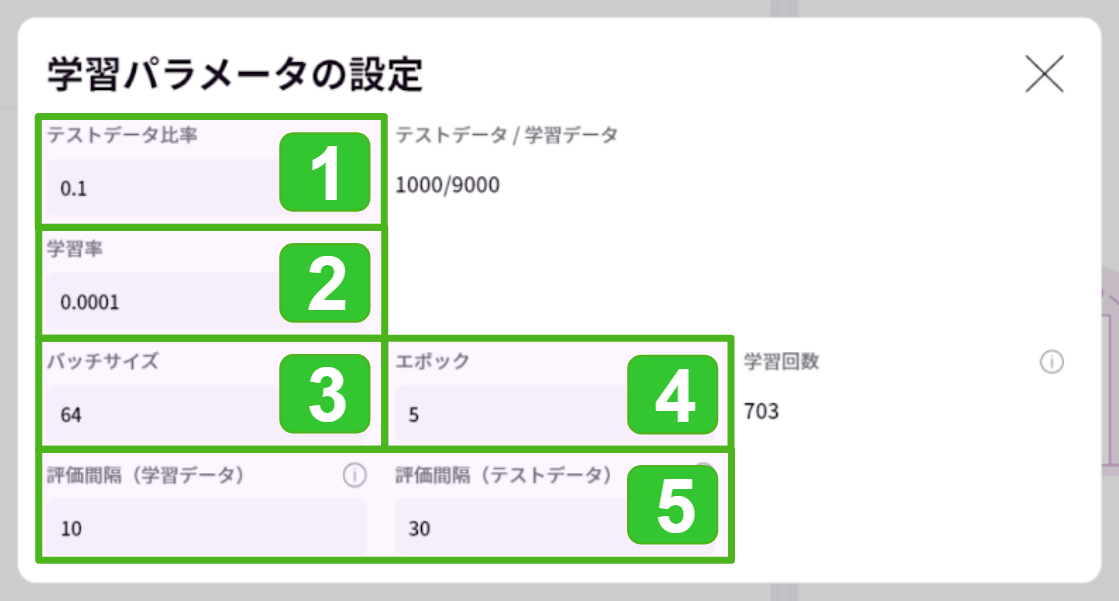
- テストデータ比率:0.1(デフォルト)
表形式データセットと同様です。 - 学習率:0.0001(デフォルト)
1回の学習で重みやバイアスのパラメータをどのくらい変化させるかを指定します。
学習が進まない(遅い、緩やか)ときは学習率を上げる、学習がすぐ終わる(早い、急速)ときは学習率を下げると、改善される場合があります。 - バッチサイズ:64(デフォルト)
1回の学習ですべての訓練データを使いますが、このときデータをランダムに複数のグループに分け、グループごとにパラメータの調整を行います。バッチサイズには、1グループあたりのデータ数を指定します。
例えば、画像データが6,000枚の訓練データでバッチサイズ:600 にすると、600枚ずつ10グループに分けられます。パラメータを調整しながら10グループ6,000枚の学習が終わると、学習回数1回です。 - エポック:5(デフォルト)
学習回数のことを「エポック数」といい、何回学習するかを指定します。
AIモデルは同じデータセットをグループ分けを変えながら繰り返し何度も読み込んで、特徴や違いを学習していきます。 - 評価間隔
学習データ:10(デフォルト),テストデータ:30(デフォルト)
指定した学習回数ごとにモデルの評価値(正解率と損失関数)を求めます。
学習中の学習グラフ、および学習終了後の[学習情報]画面に表示される、正解率と損失関数グラフのx軸です。グラフは学習データの一部(=評価値を求めるタイミングで使っているデータ)とテストデータ、それぞれを使って求めた評価値をプロットします。
※評価間隔が小さすぎると、処理が重くなり学習が遅くなります。