このセクションの他の記事
ファインチューニングとは
ファインチューニングブロックは、画像の学習に用いるブロックです。
ファインチューニングは、既存の機械学習モデル(特に大規模な深層学習モデル)に対して、特定のタスクやデータセットに適応させるために追加の学習を行うプロセスのことです。
大規模モデルをゼロから学習させるには膨大な計算リソースが必要ですが、大規模データで事前学習済みのモデルを利用すれば、少量のデータでも高精度な結果を得られます。
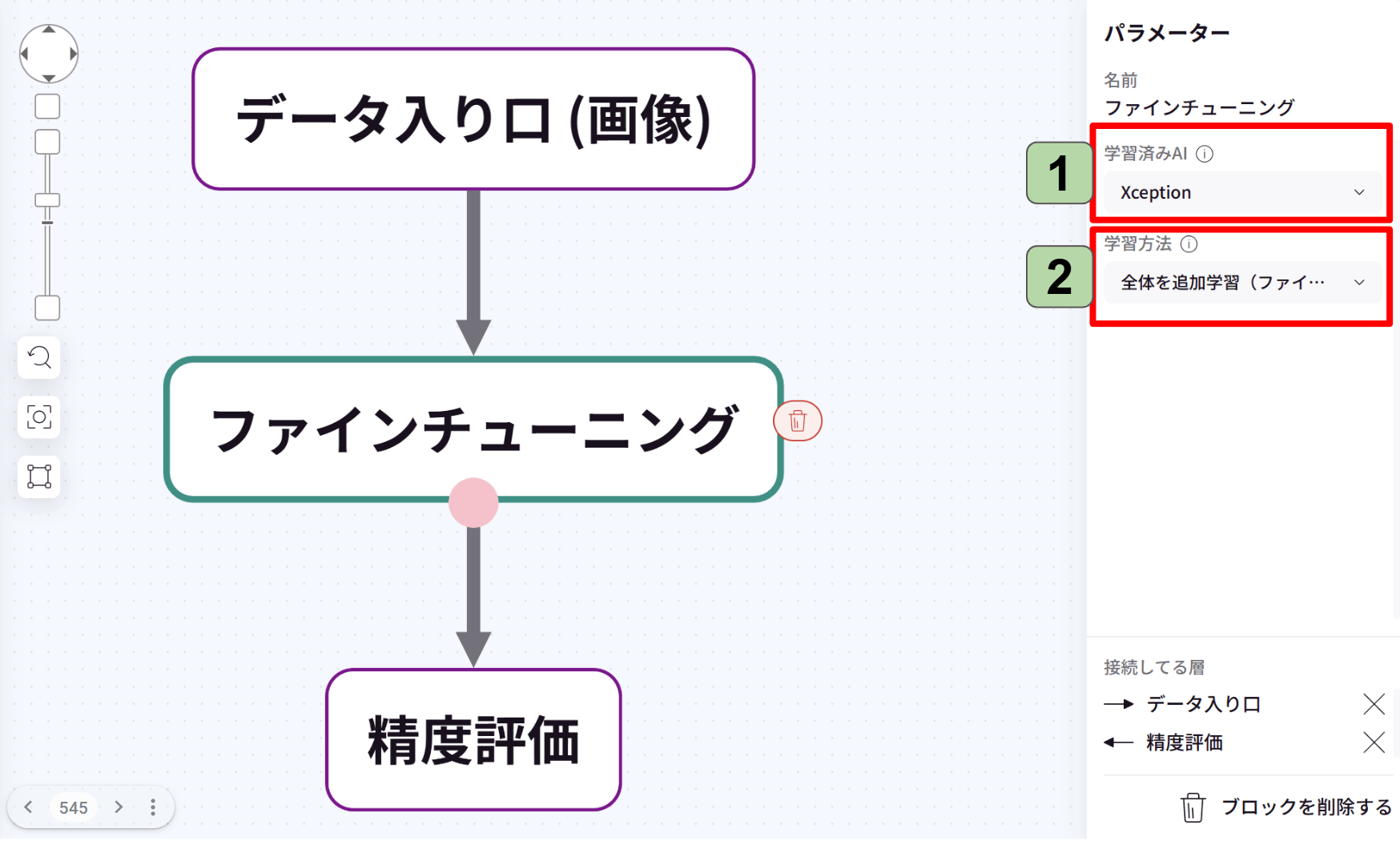
ファインチューニングブロックは、ブロックタイプ「追加学習」に格納されています。
1.学習済みAIは「Xception」「InceptionV3」「VGG16」「ResNet50」「MobileNetV2」から選べます。
それぞれのメリットをご紹介します。
Xception:計算コストを削減しつつ高い精度を実現。シンプルな構造で、高速かつ高精度。
InceptionV3:画像の特徴を多様なスケールで捉えられる。モデルサイズの割に高い認識能力を持ち、実績が豊富。
VGG16:事前学習済みモデルが広く利用されており、他のタスクに適用しやすい。計算コストが高いので、転移学習を活用したい場合(特に学習データが少ないとき)におすすめ。
ResNet50:多くの画像認識コンペで優秀な成績。計算コストがやや高いが、勾配消失問題を解決。非常に深いネットワークでも学習可能。
MobileNetV2:精度と計算量のバランスが取れている。ResNet50やXceptionほどの高精度は得られないが、軽量かつ高速なモデルが求められる環境に良い。
2.学習方法は「全体を追加学習(ファインチューニング)」「一部を追加学習(転移学習)」から選べます。
ファインチューニング:全ての層のパラメータを更新する方法です。計算コストが高いですが、最適なパフォーマンスを得られる可能性があります。(高コスト・高精度・元の知識を忘れやすい)
転移学習:一部の層だけを学習します。計算コストが低く、元の知識を活かしやすいです。(低コスト・元の知識を保持しやすい)
いちからAIを作成するとなると、膨大なデータセットと計算コストが必要となります。しかし、あまり良い精度が出せないケースが多々あります。
ファインチューニングブロックは、少数のデータセットでも高精度のAIを作成することができます。
「膨大なデータセットが用意できない」「計算コストを抑えてたい」でも「精度の高いAIが欲しい」を求める方におすすめです。