このセクションの他の記事
数値に変換する
表形式データ(CSVファイル)を投入する場合、[学習に使用する列][予測する列]は文字列のままでは使用できないため、数値に変換します。
変換できるのは、値をルールに従って数値に置き換えできる文字列です。
■数値に変換する
[前処理]画面で各列の「前処理内容の編集」をクリックして[列の詳細]画面へ遷移します。
[列の詳細]画面で「数値に変換する」の矢印(右図の赤枠)をクリックすると、数値変換のメニューが表示されます。
表示されたメニューの矢印(同青枠)をクリックすると、処理メニューが表示されます。

次からは、各処理がどのような処理を行うのか、詳しく解説します。
■One-Hotエンコーディング
One-Hotエンコーディングは、区別や分類を表す大小関係のない(=名義尺度)カテゴリーデータを変換するのに向いています。列に含まれる値を新たな列として値の数分生成し、値に該当する列を「1」、残りの列をすべて「0」に変換します。
このとき、MatrixFlowでは欠損値に対応するため、必ず「〇〇_nan」列も生成します。
<補足>[nan]は「Not A Number」の略で、データが存在しない「欠損値」を意味します。
1列で表現できるのを複数列で表現し直しているので一見複雑に見えますが、0と1だけで表現できるため数値の大小に影響されることなく、すべての値が平等に扱えるというメリットがあります。
逆に、列数が多くなるデメリットもあります。列が多くなると、計算量が増えるため学習が終わらなくなったり、学習効率が悪くなったりするので、データの傾向を確認しながら処理を行いましょう。
One-Hotエンコーディングを行った列は、元の列は削除され、変換後の列はデータセットの最後部に生成します。列名は、自動で「{元の列名}_{値}」の形式で付けられます。
変換例)「性別」列に「男, 女」2つの値があるとします。
値が「男」であれば「性別_女」列を「0」、「性別_男」列を「1」、「性別_nan」列を「0」に変換します。
値が「女」であれば「性別_女」列を「1」、「性別_男」列を「0」、「性別_nan」列を「0」に変換します。

■ダミーコーディング
ダミーコーディングも、値に大小関係のないカテゴリーデータを変換するのに向いています。One-Hotエンコーディングと同じように、値に該当する列を「1」、残りの列をすべて「0」に変換します。One-Hotエンコーディングと異なるのは、新たに生成する列が「列に含まれる値のユニーク数から-1」した数の列を生成する点です。‐1される列(参照カテゴリと言います)はシステムが自動で決定しますが、変換後の生成された列の値がすべて「0」のとき、その値は参照カテゴリの値であると判断します。
なお、必ず「〇〇_nan」列を生成する点はOne-Hotエンコーディング同様です。
ダミーコーディングを行った列は、元の列は削除され、変換後の列はデータセットの最後部に生成します。列名は、自動で「{元の列名}_{値}」の形式で付けられます。
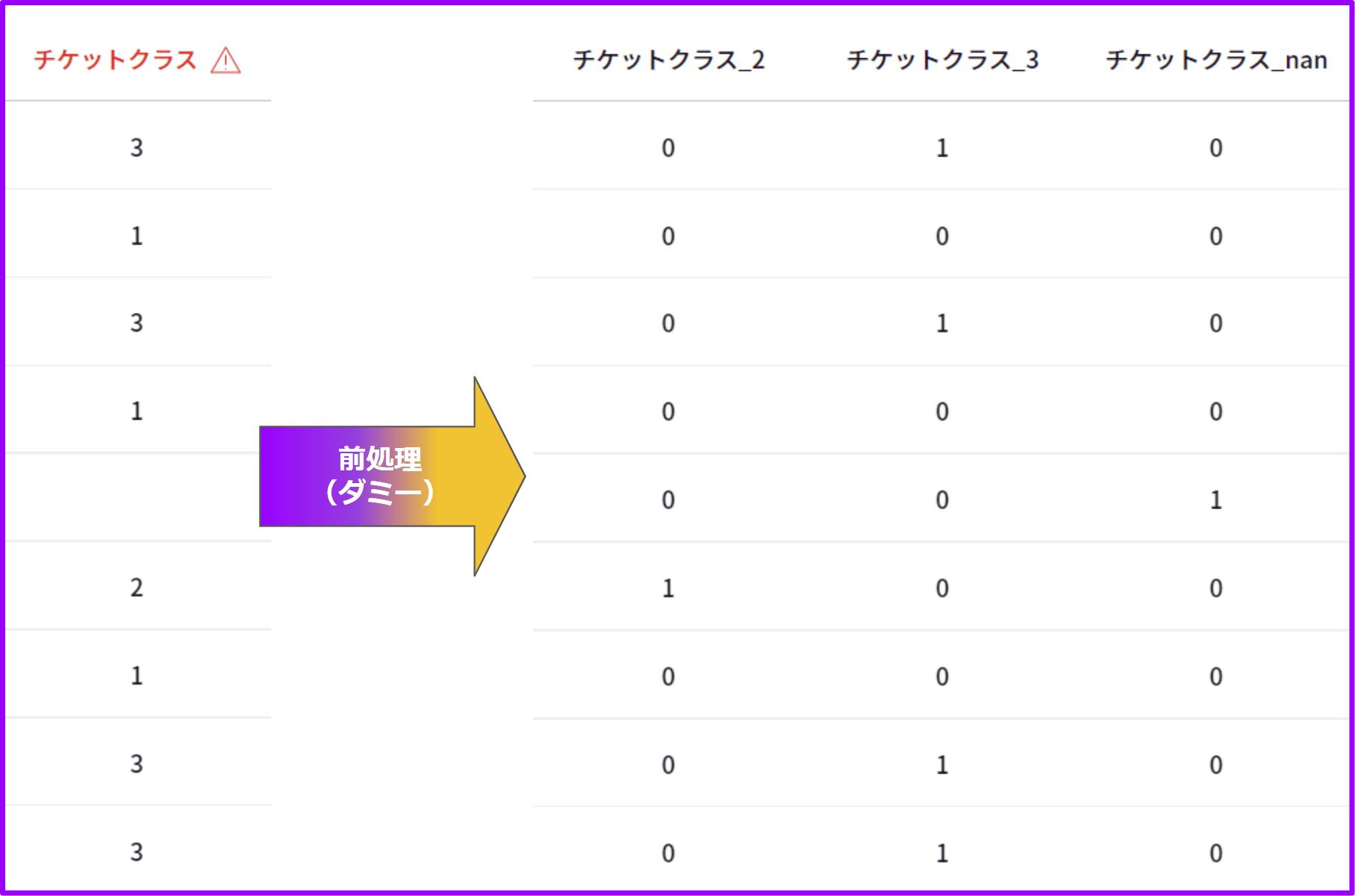
変換例)「チケットクラス」列に「1, 2, 3」3つの値があるとします。
また、参照カテゴリは「1」に決定されました(=「チケットクラス_2」「チケットクラス_3」「チケットクラス_nan」列が生成されます)。
値が「2」であれば「チケットクラス_2」列を「1」、「チケットクラス_3」列を「0」、「チケットクラス_nan」列を「0」に変換します。
値が「1」であれば「チケットクラス_2」列を「0」、「チケットクラス_3」列を「0」、「チケットクラス_nan」列を「0」に変換します。すべての列が「0」のため、チケットクラスの値は「1」であると判断できます。
■ラベルエンコーディング
ラベルエンコーディングは、区別や分類を表す大小関係のある(=順序尺度)カテゴリーデータを変換するのに向いています。各カテゴリの値に単純に数値を割りあてます。
上述2つのように新たな列は生成しません。また、ラベルエンコーディングを行った列の位置や列名も変わりません。
変換後の数値は、システムが値を昇順に並び替え「0」から割りあてますが、任意の値を手入力して指定することができます。
<重要>
ラベルエンコーディングのみ、列内のデータに欠損値がある場合、先に欠損値の補完を行ってください。欠損値が存在するまま処理を実行すると、失敗します。
※1つの列に複数回、異なる前処理を適用できます。
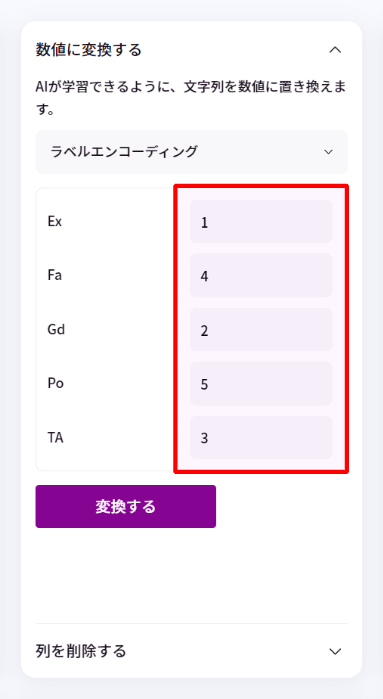
変換例)「外装の素材の良さ」列に「Ex, Gd, TA, Fa, Po」5つの値があるとします。
順番に「Excellent, Good, Average/Typical, Fair, Poor」を意味し、大小関係があるので、それぞれ「1, 2, 3, 4, 5」に変換します。

■共通の重要事項
いずれの方法でも、学習データにはすべての種類のカテゴリーデータを含めてください。
カテゴリーが足りないまま保存した前処理設定を推論データに適用すると、エラーになり先に進めません。
保存した前処理設定の編集はできないため、学習をし直して 前処理設定を作り直すことになります。