




はじめに
今回はMatrixFlow上で、AIの分析手法である「自然言語分類」を使用し、ニュース記事を自動で分類するAIを作っていきます。
AIを作るといっても、MatrixFlowを使えばプログラミングをする必要はありません。
ノンプログラミングで、簡単にテキストデータを分類することが可能です。
さっそく、AIを作っていきましょう。
◆目次◆
1. 題材と分析手法の説明
2. プロジェクトの説明
3. AIを作成する流れの全体像の説明
4. データセットの説明
5. レシピ
6. 学習
7. 学習結果
8. 推論
9. まとめ
1. 題材と分析手法の説明
使用するAIの分析手法は、「自然言語分類」です。
自然言語分類は、テキストデータの中にある、文章の内容を分析し、それを設定したカテゴリーに分類する手法です。機械学習を用いると、大量のテキストデータの解析など、マーケティング分野や業務の自動化・効率化などで用いられています。
この記事では題材として、実際のニュース記事のテキストデータを使用し、MatrixFlowで学習を行い、ニュース記事を自動で分類してみましょう。
2. プロジェクトの説明
それではさっそくAIを作っていきましょう。
プロジェクトは作成したAIや、AIの作成に使用したデータセットやレシピなどを管理する単位です。フォルダのようなイメージです。
AIの作成を進めていくと、使用したデータセットやレシピなどが、プロジェクトの中に保存されていきます。
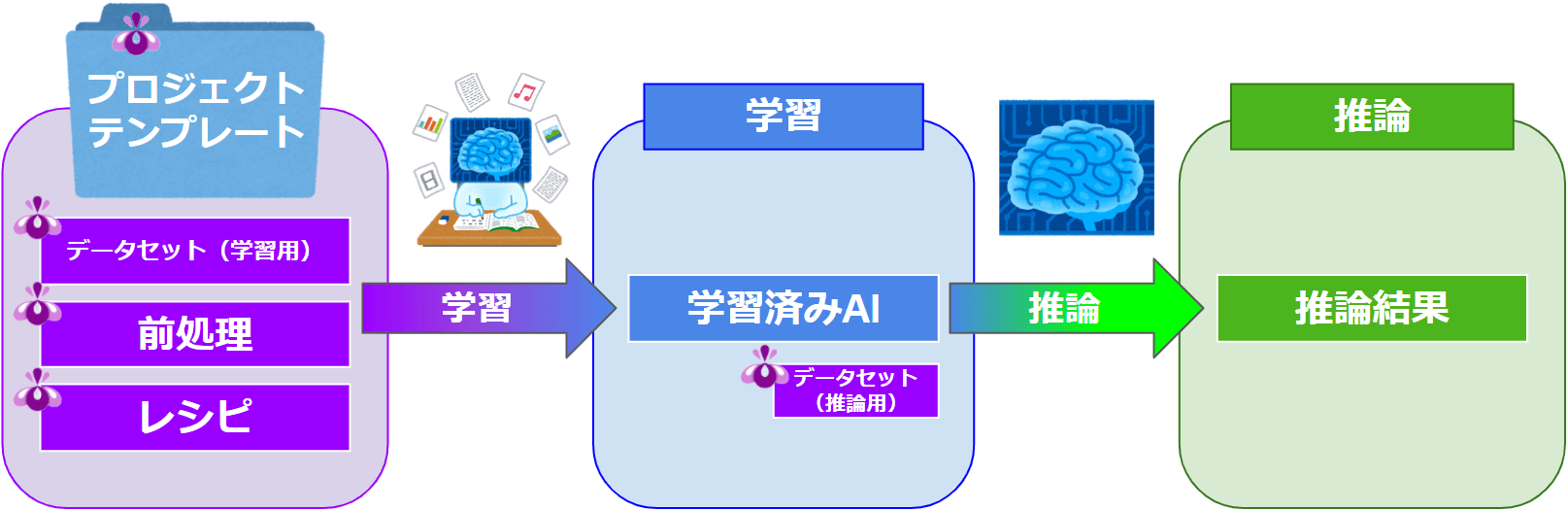

3. AIを作成する流れの全体像の説明
AIを作成する流れは以下のようになっています。
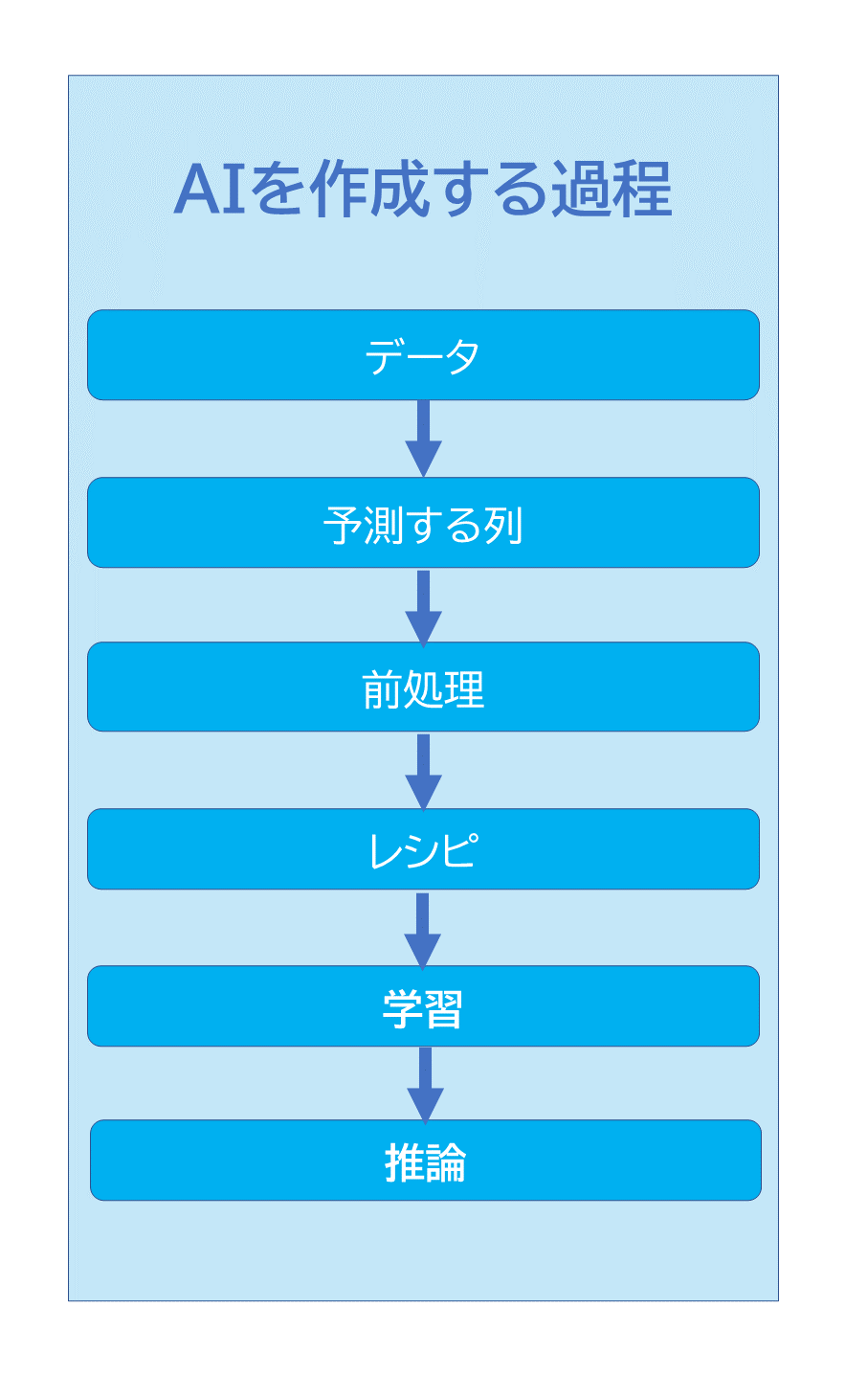

※今回の例では「予測する列」と「前処理」のステップは不要です。「予測する列」とは、AIで予測したいデータセットの列です。予測する列は、作成するAIの重要な設定事項です。なお、「前処理」とは、AIが学習を行えるように、データを加工することを「前処理」と言います。
AIを作成するには、まずは学習させるデータセットが必要になります。ここからいよいよ、AIの設計図である「レシピ」を作成した上で、学習を行いAIを作成します。推論することで、求めたい結果を得ることができます。
ではさっそくMatrixFlowを操作してみましょう。
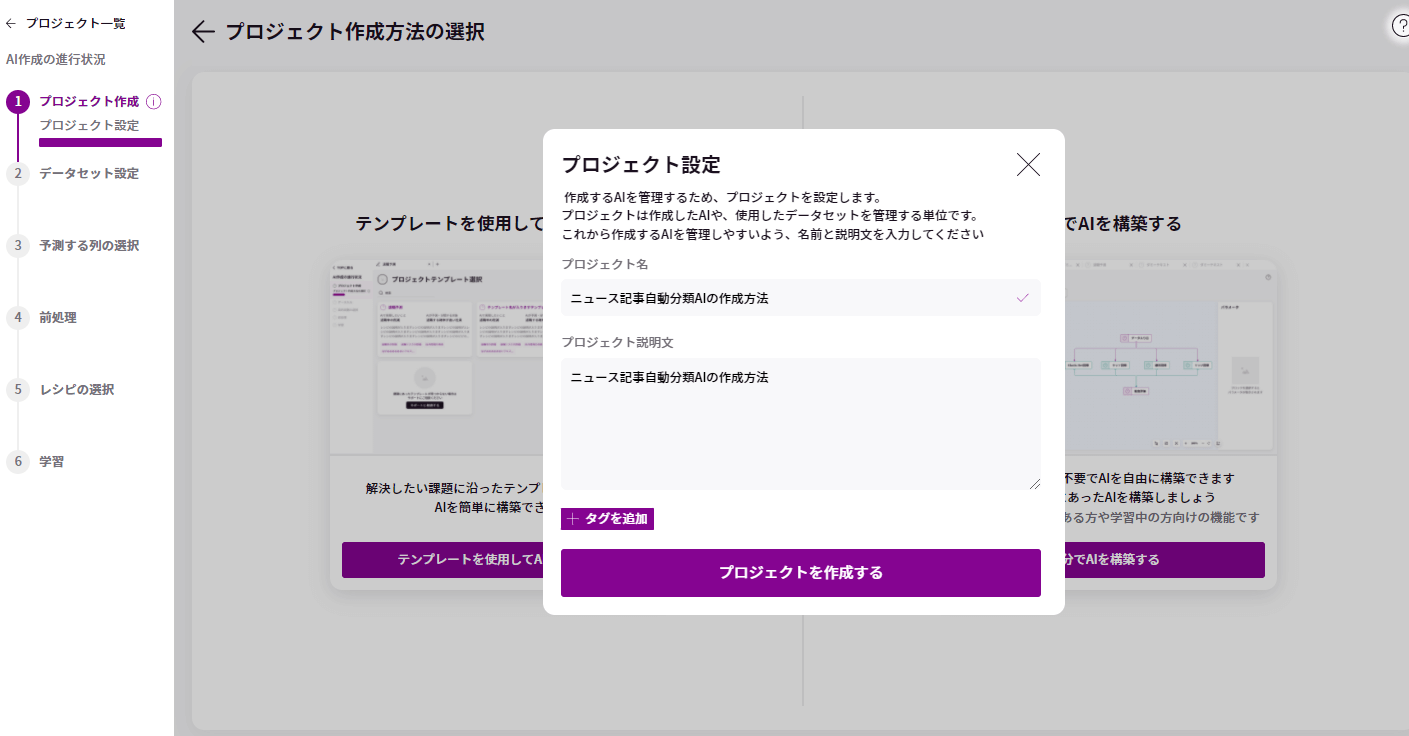
MatrixFlowにログインし、はじめに、プロジェクトを作成します。
プロジェクト一覧から「新規プロジェクトを作成する」をクリックします。

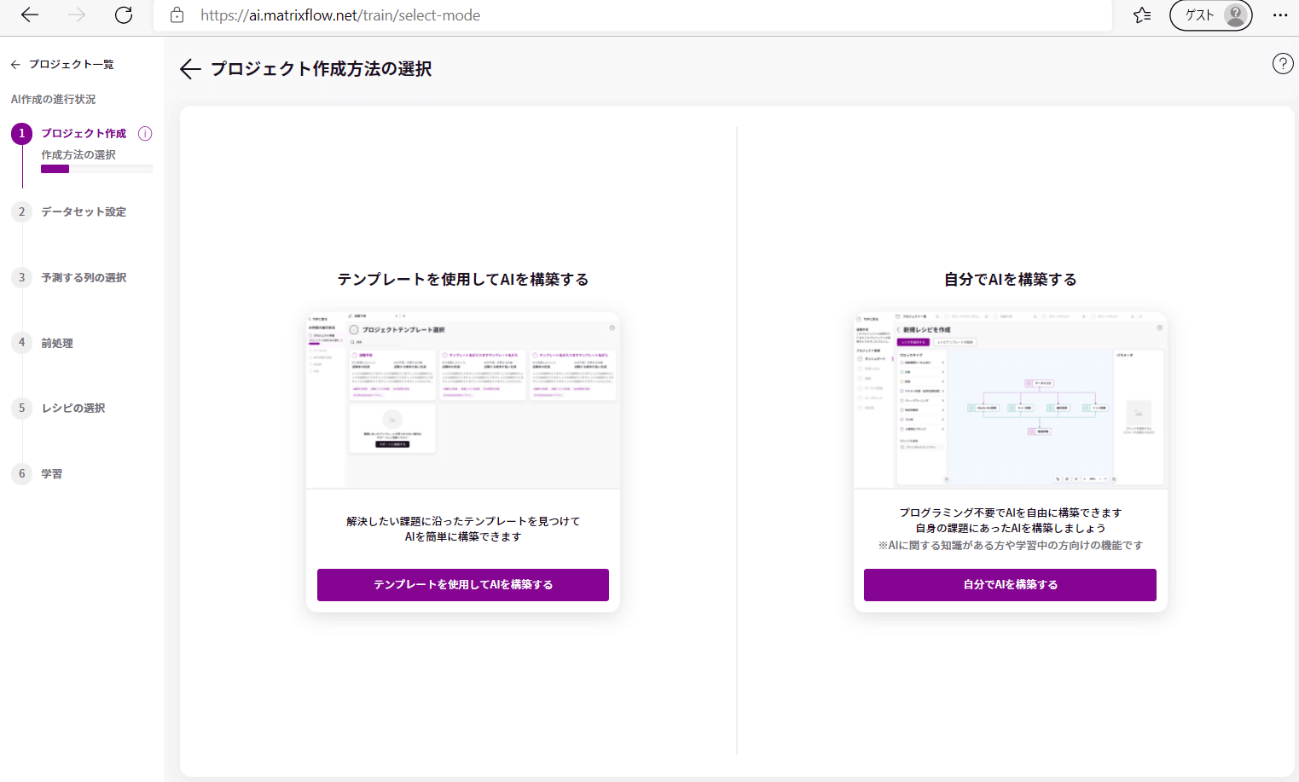
「テンプレートを使用してAIを構築する」または「自分でAIを構築する」のどちらかを選択します。ここでは、「自分でAIを構築する」を選択しましょう。

プロジェクト名とプロジェクトの説明文を入れて作成します。

4. データセットの説明
学習させるデータを用意します。無料で入手できるニュース記事のデータセットはいくつかありますが今回はlivedoor ニュースコーパスを使います。データセットの内容は以下のようなものになっています。
さらにニュースは9つのカテゴリに分かれているので、ニュース記事本文とカテゴリのラベルを使って、教師あり学習で学習させます。なお、カテゴリは以下の通りです。
・トピックニュース
・Sports Watch
・ITライフハック
・家電チャンネル
・MOVIE ENTER
・独女通信
・エスマックス
・livedoor HOMME
・Peachy
ldcc-20140209.tar.gz をダウンロードしたあと、zipを解凍し、カテゴリごとに分かれたフォルダにニュース記事が入っていることを確認します。
次にMatrixFlowにアップロードするためのzipファイルを作ります。
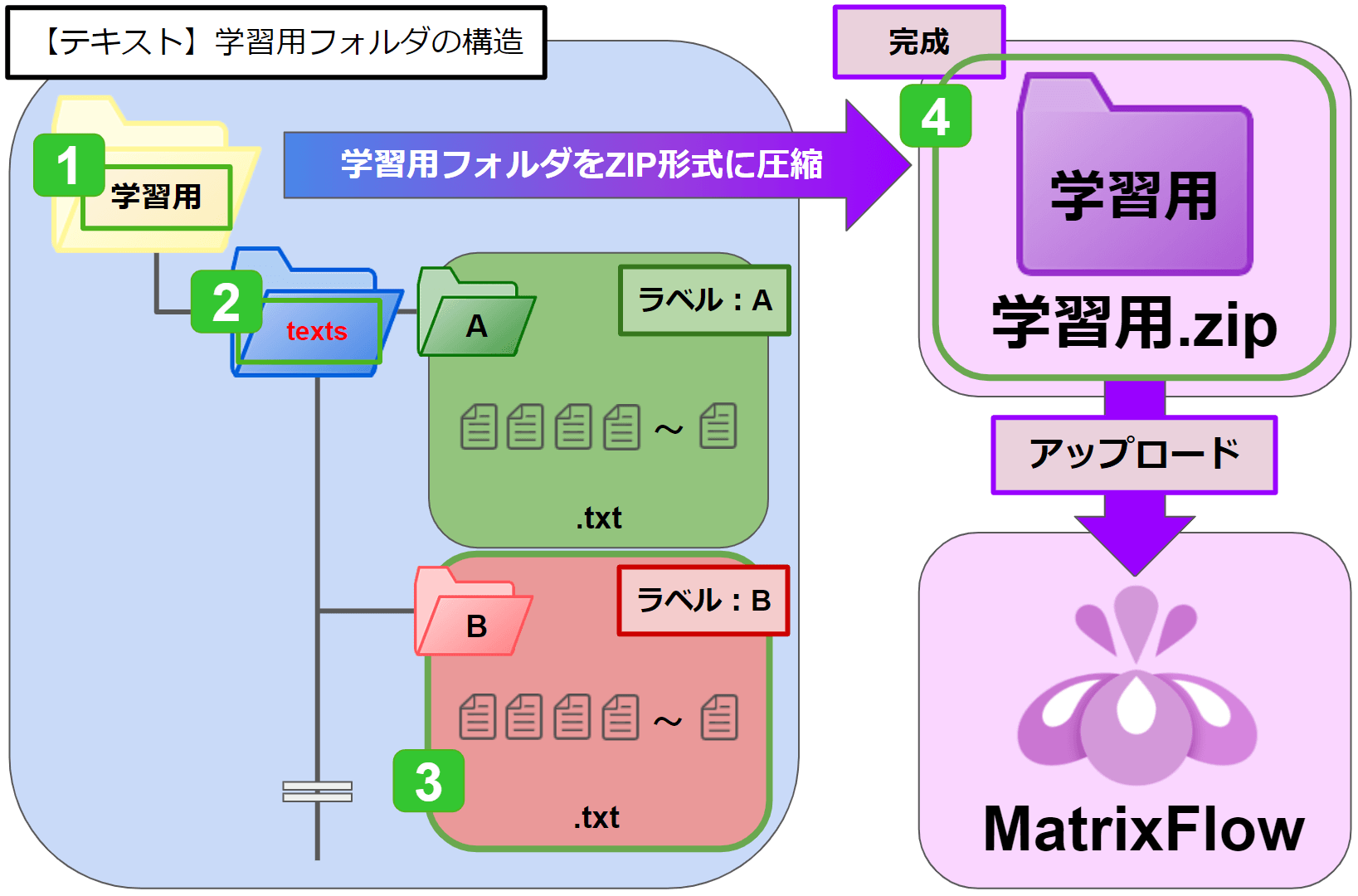

まず、テキストを入れるフォルダをつくりましょう。構造、作り方は以下の通りです。
<フォルダ構造>
フォルダ/textsフォルダ/列(ラベル)フォルダ/テキストデータ
1.一番上に位置するフォルダです。任意のフォルダ名を付けて下さい。(例:学習用)
2.1の配下のフォルダです。テキストの場合 texts とします。
3.textsフォルダの配下のフォルダです。
任意のフォルダ名を付けて下さい。これが列名(ラベル)となります。
その中に列名(ラベル)に沿ったテキストを入れましょう。
今回の場合、例えば、Bのフォルダ名を「topic-news」にして、
そのフォルダにトピックニュースの記事を投入する事で、
AIがトピックニュースのテキストとして学習することができます。
4.1のフォルダをZIP形式に圧縮します。ZIP形式のデータにすることで、データセットとして使用する事が出来ます。
今回のデータセットですとすでにカテゴリに分かれているため、そのまま使います。また、各フォルダに入っているLICENSE.txtを忘れずに除きましょう。
これらのzipファイルの詳細はMatrixFlow操作マニュアルにも書いています。
このデータセットをつかって、MatrixFlow上でAIを作ってみましょう!
<データのアップロード>
データセットの設定を行います。使用するデータを設定するには、3つの方法がありますが、今回は「ファイルをアップロード」を使用します。
上記で用意したzipファイルを所定のエリアにドラッグ&ドロップします。
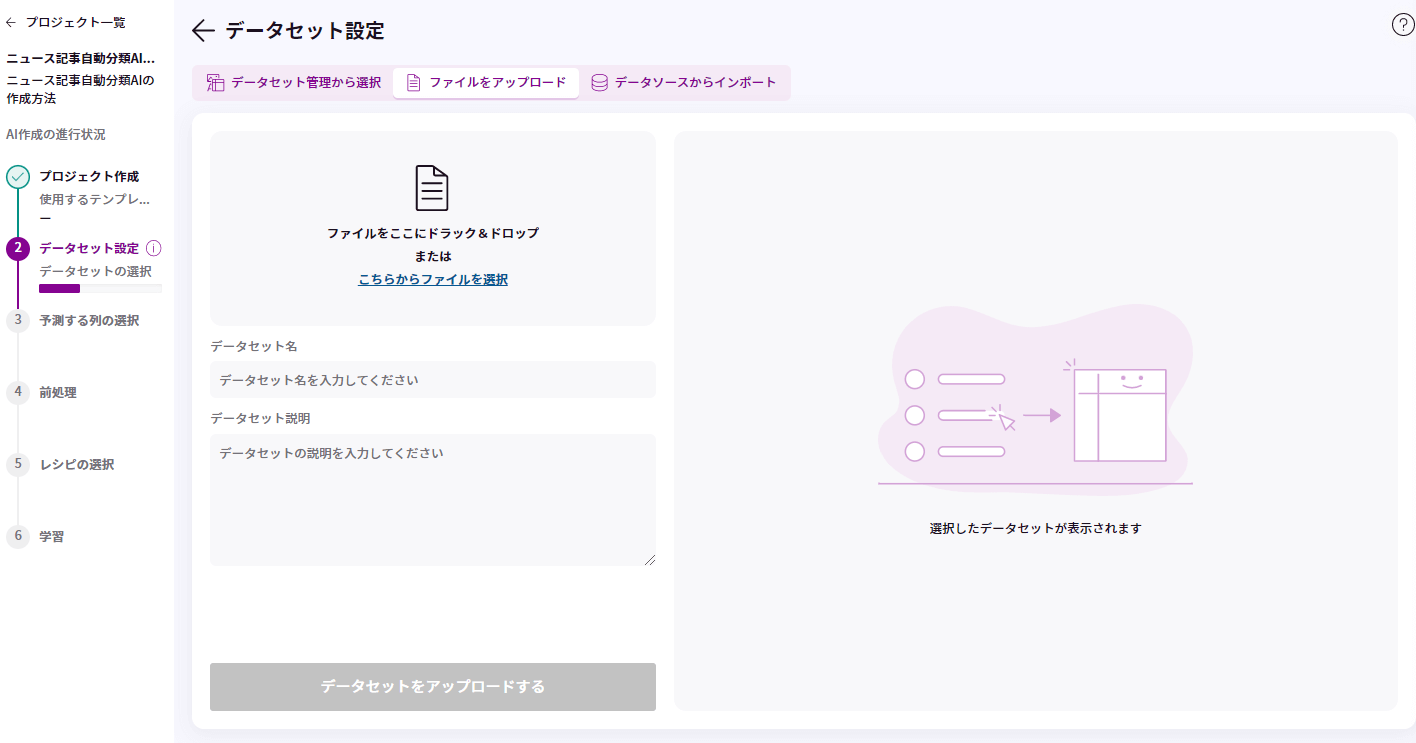

データを取り込めたら、ファイルの情報が表示されますので、名前と説明を入力して「データセットをアップロードする」をクリックしましょう。
5. レシピ
データの準備ができたので、AIの設計図である「レシピ」をつくっていきましょう!
レシピ管理のページで、「新規レシピを作成」ボタンをクリックします。
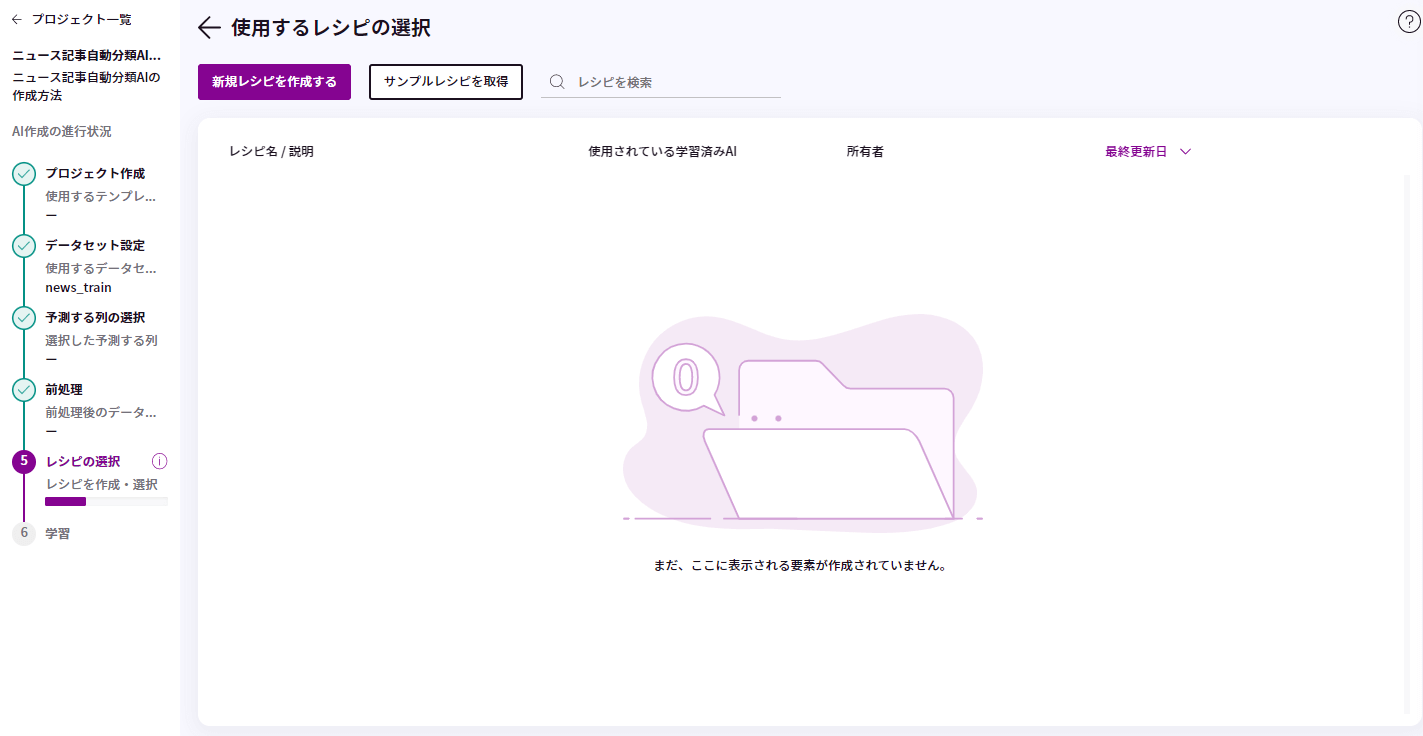

ここでは、「テキスト処理(自然言語処理)」を使用します。自然言語処理とは、文章をコンピューターが分析できる形式に変換する処理です。
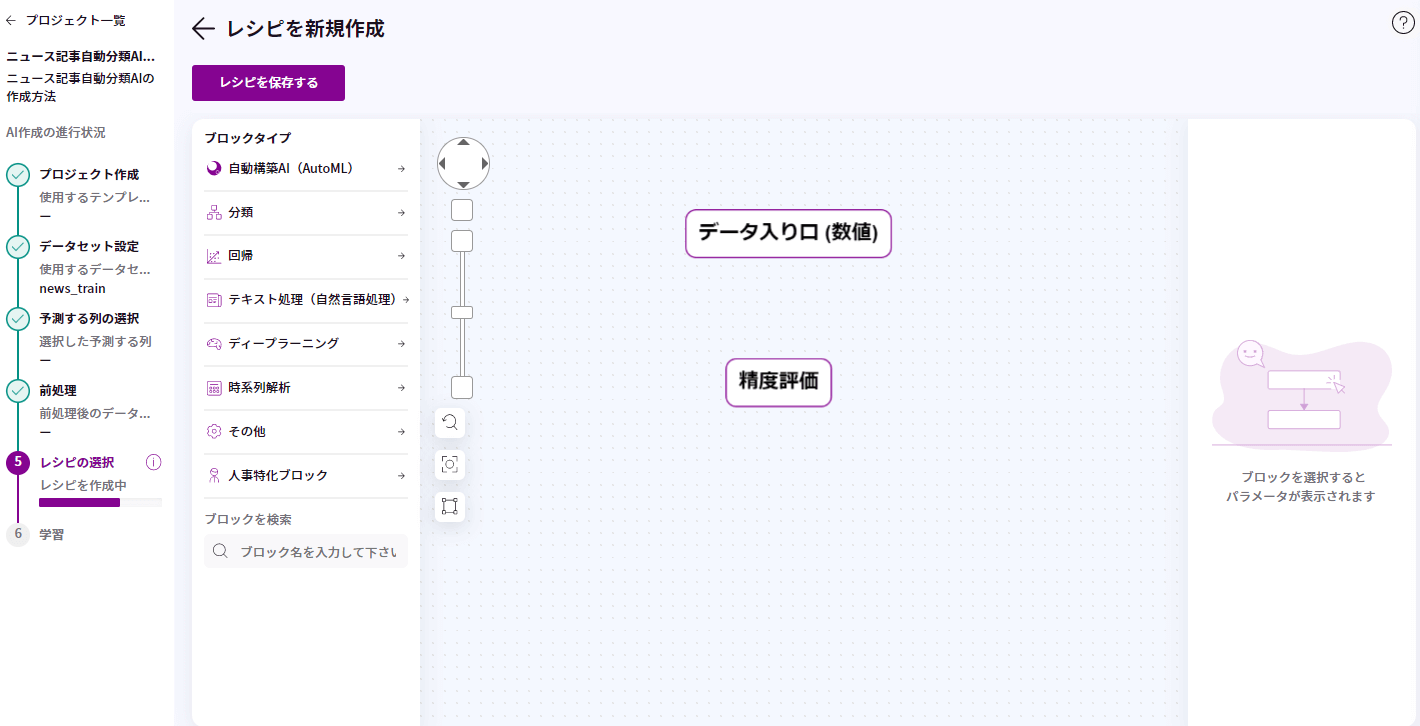

レシピ作成画面で、左のメニューの「テキスト処理(自然言語処理)」をクリックします。
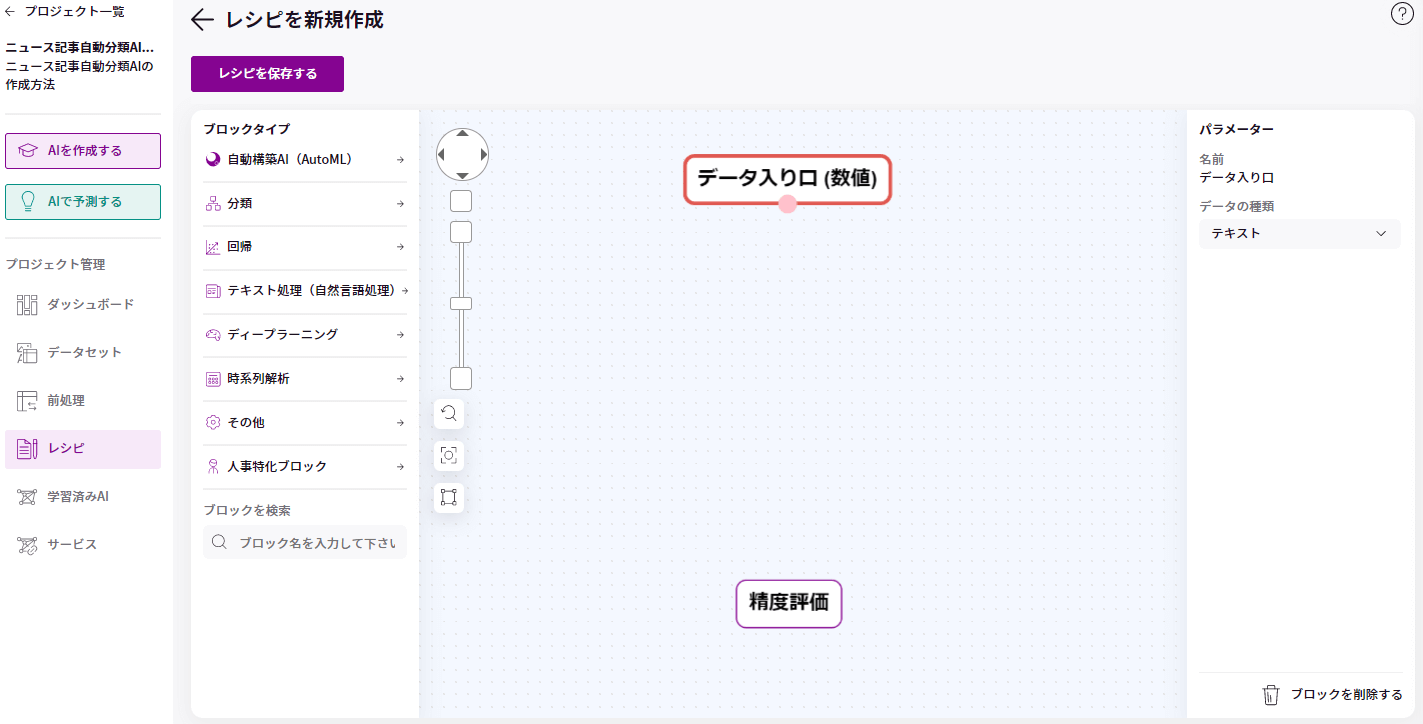

「データ入り口(数値)」のブロックをクリックし、右のパラメータ欄にあるデータの種類を「テキスト」に変更します。
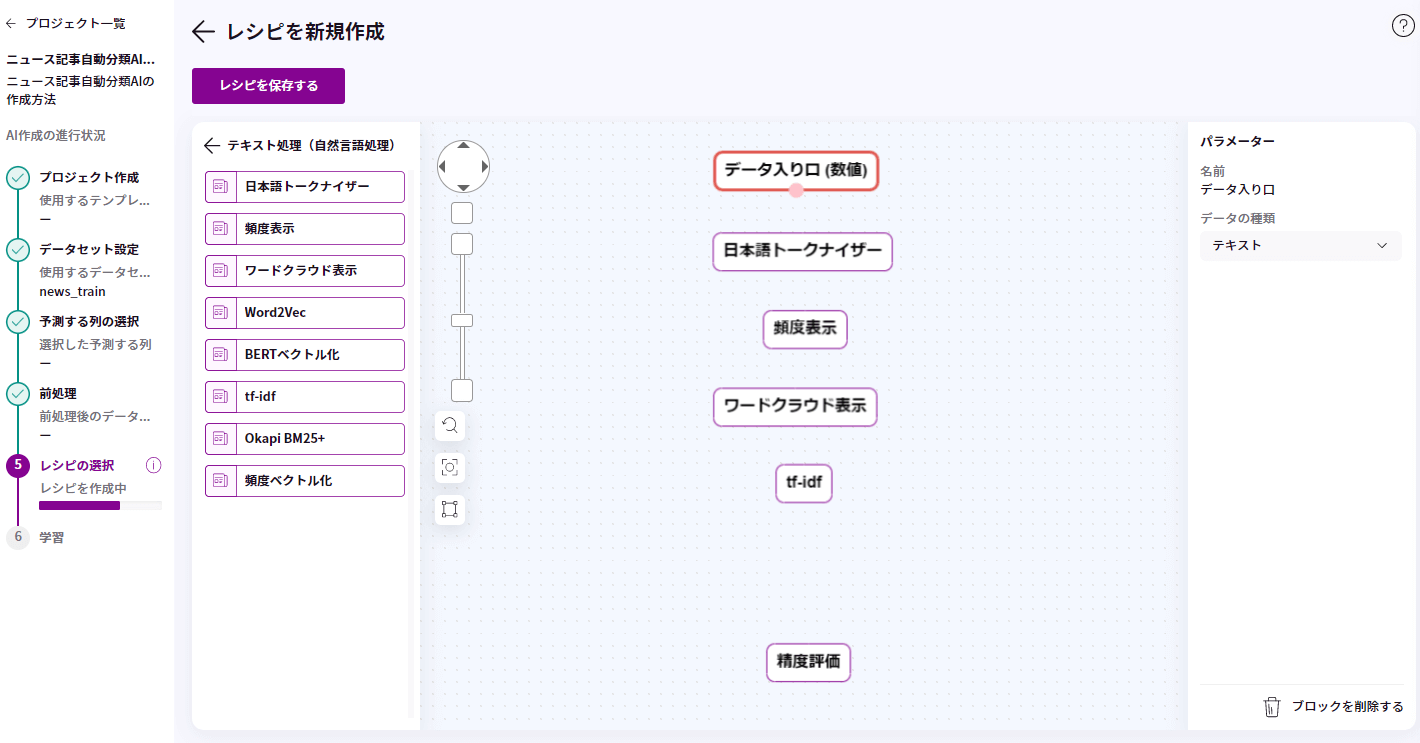

画面の青の領域に「日本語トークナイザー」、「精度表示」、「ワードクラウド」、「tf-idf」の順に左のメニューからドラッグ&ドロップします。
ブロックにポインターを合わせるとピンクのマルが出てきますので、つなぎたいブロックまでドラッグします。
左のメニューの「←テキスト処理(自然言語処理)」をクリックし、前のメニューに戻ります。
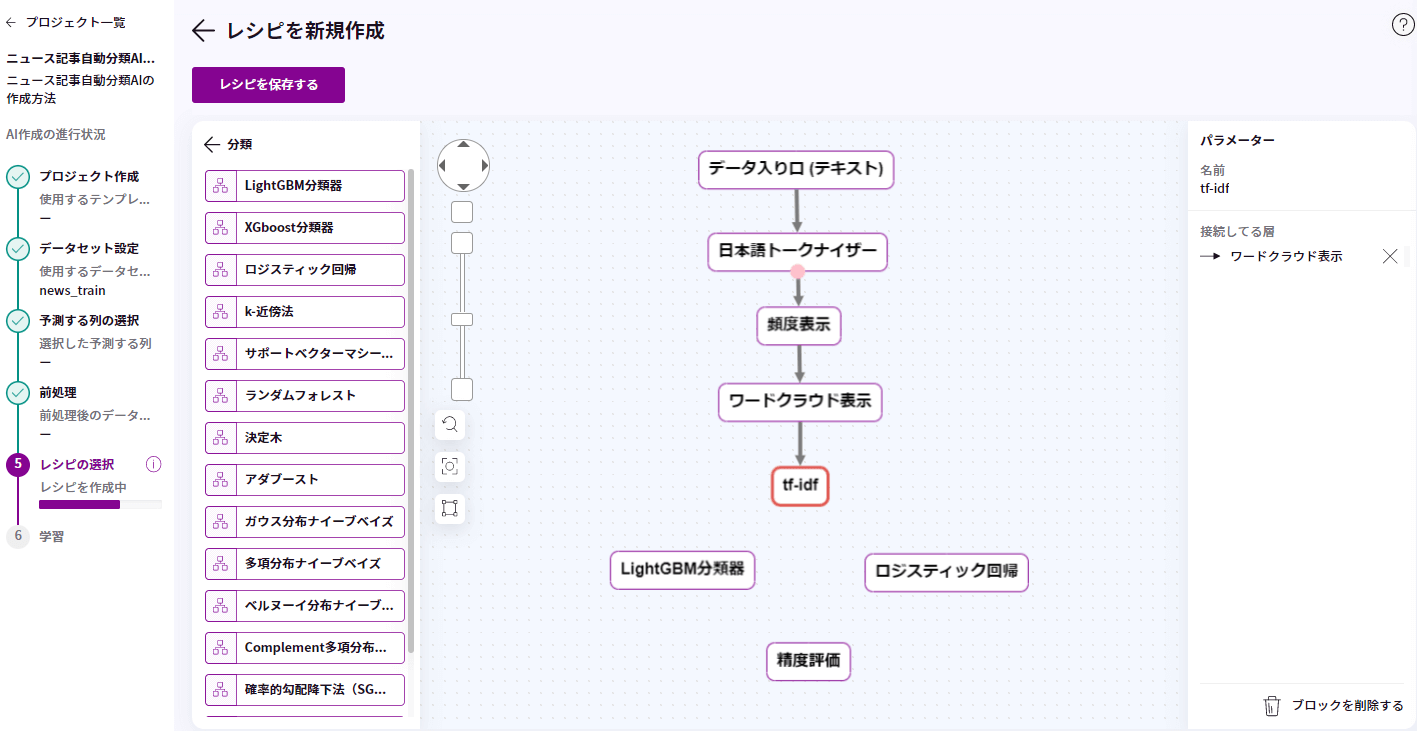

左のメニューの「分類」をクリックし、青の領域に「LightGBM分類器」、「ロジスティック回帰」をドラッグ&ドロップします。
こちらも、ピンクの丸からつなぎたいブロックまでドラッグし、各ブロックをつなげます。
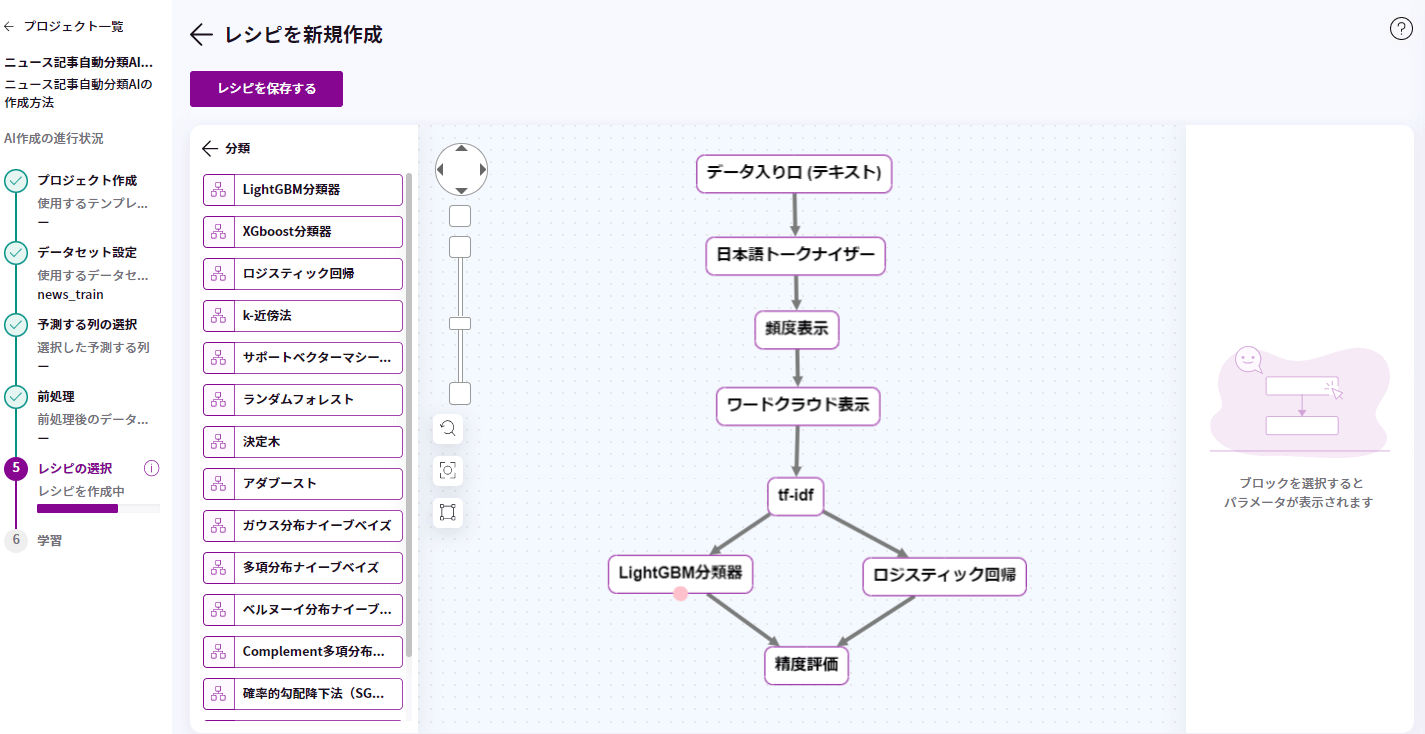

矢印がつながったら、「名前」と「説明」を入力して、「レシピを保存」ボタンをクリックし、保存します。
これでレシピの用意は完了です!
なお、今回作成したレシピは「レシピ管理」画面のサンプルレシピにも入っています。
6. 学習
「学習を実行する」をクリックすると学習が始まります。
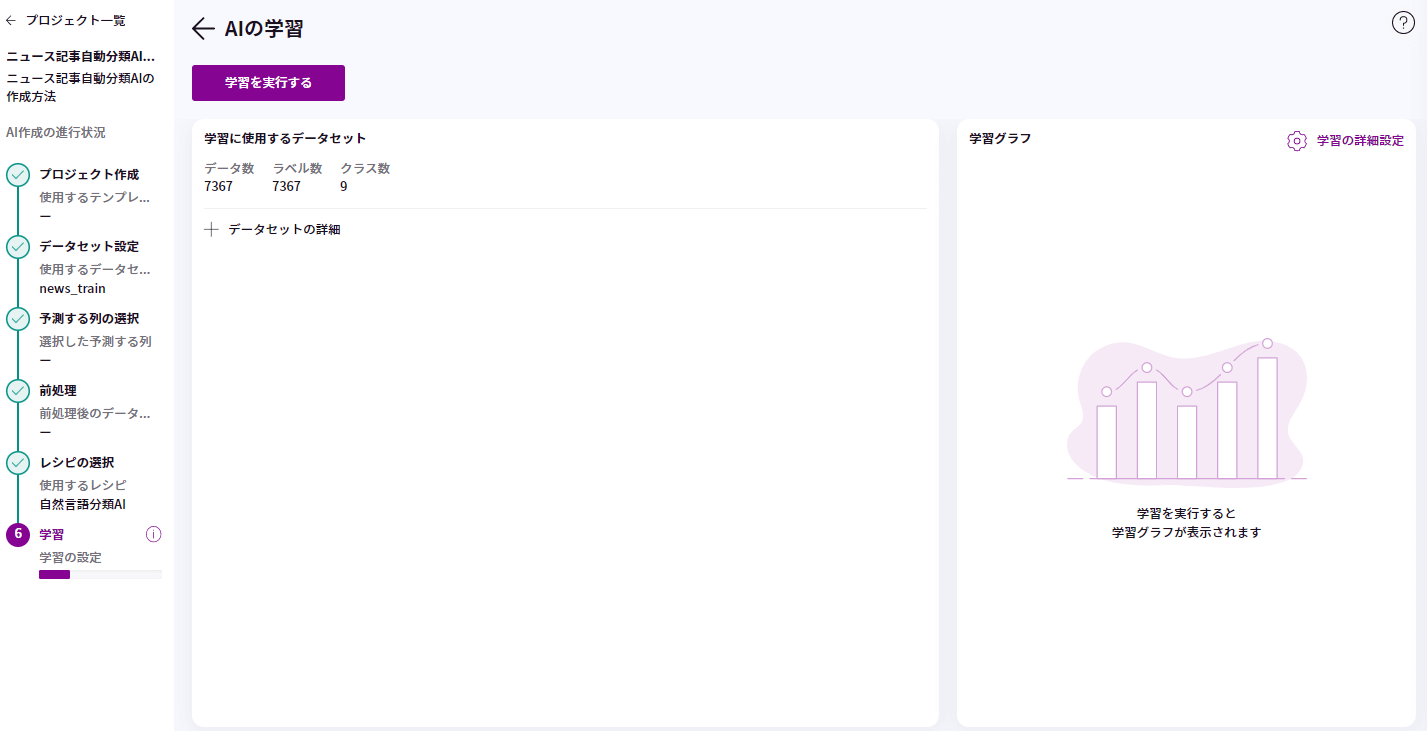

結果は少し時間をおくと、数分で表示されました。
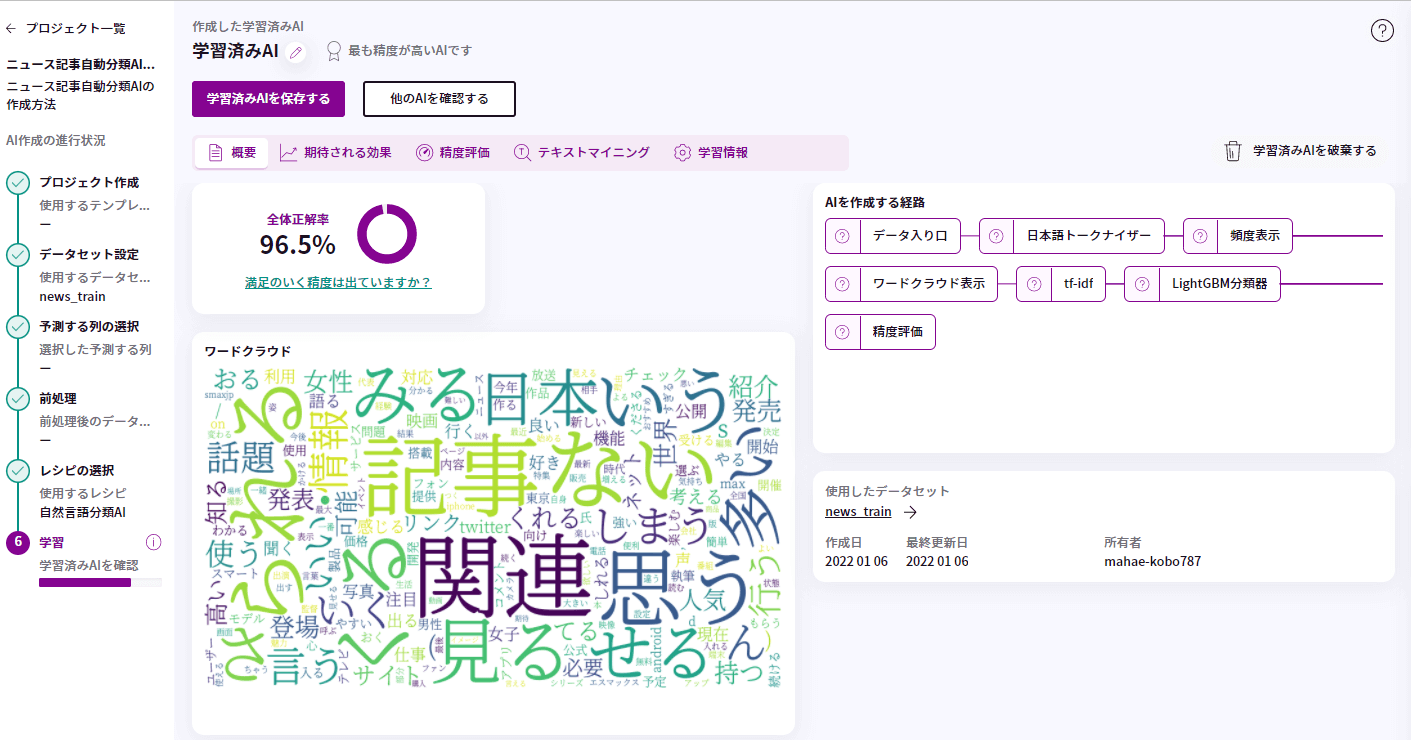

7. 学習結果
精度評価を確認するため、もう一度学習結果について、見てみましょう。
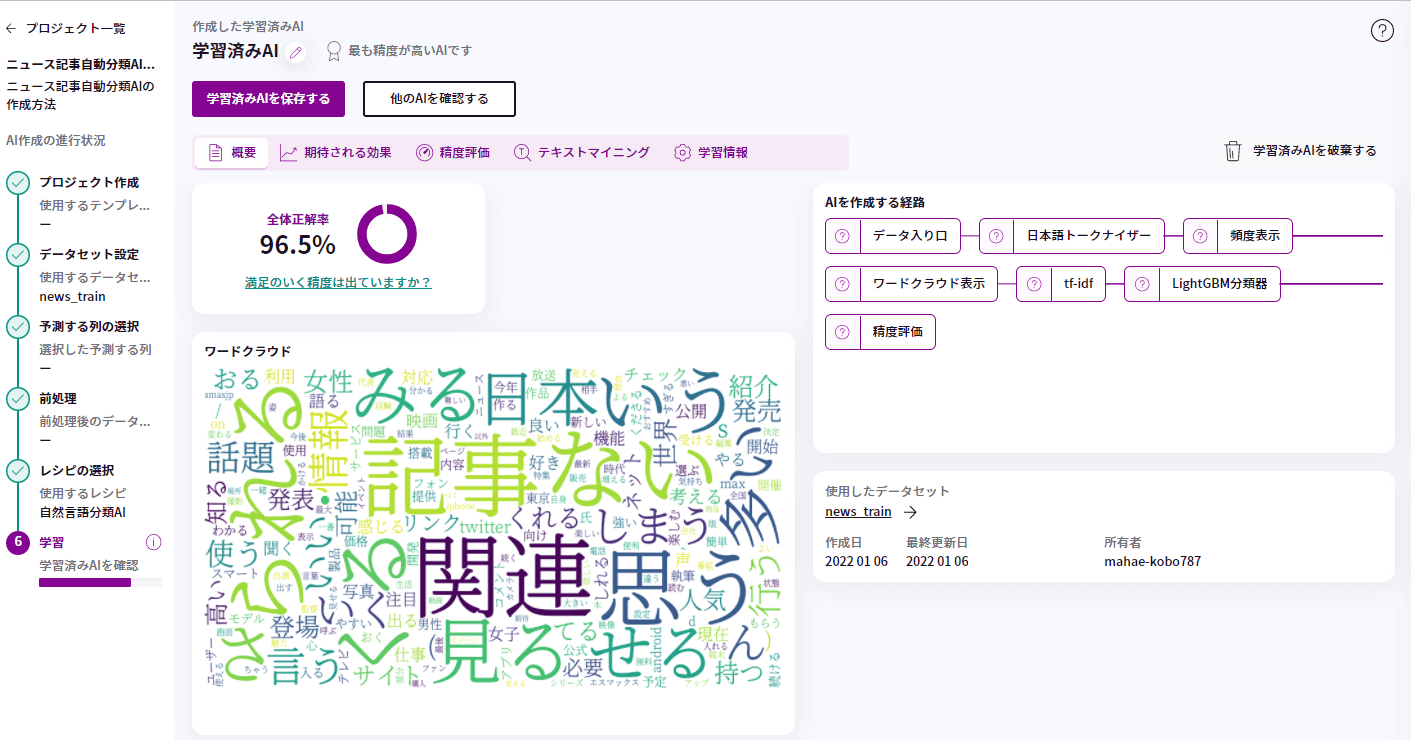
今回のAIでの学習の全体正解率は「96.5%」となっています。
上のメニューから「精度評価」をクリックし、結果を見てみましょう。
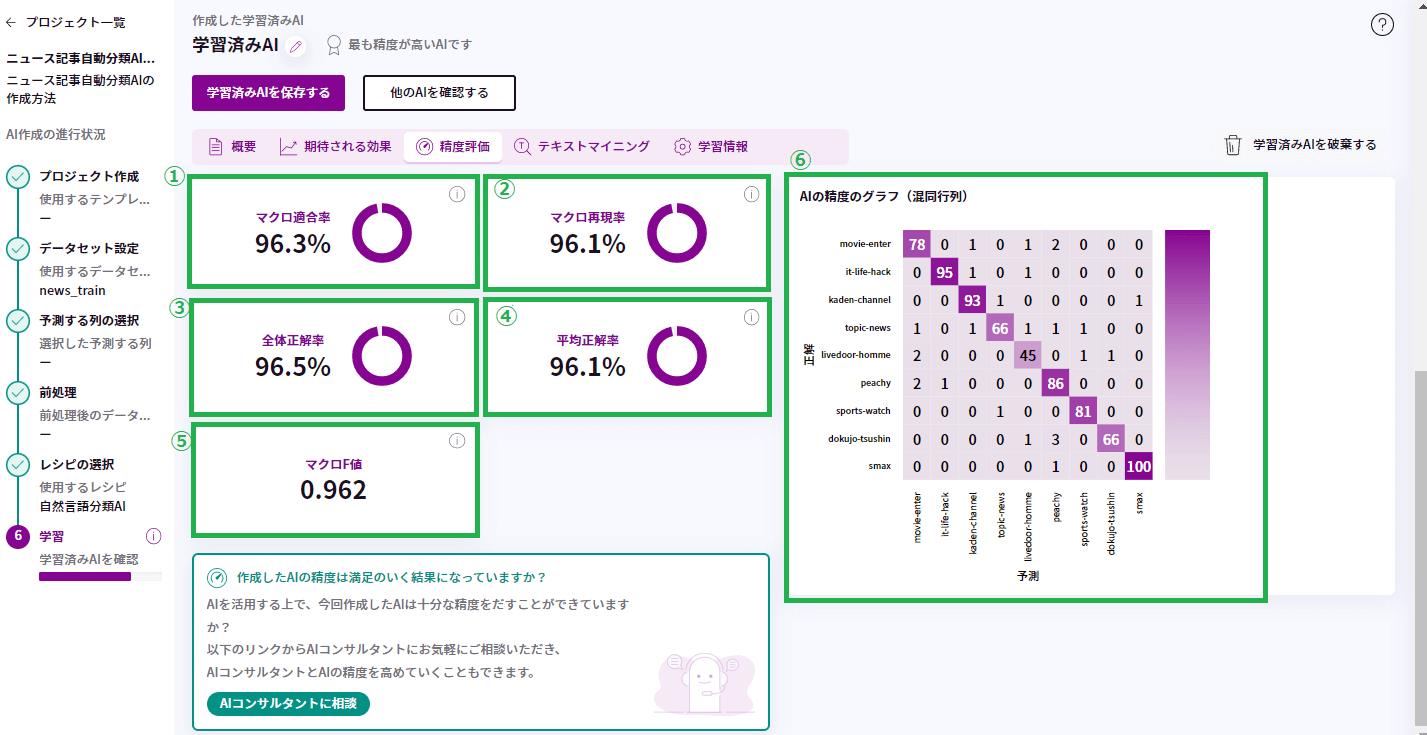

①マクロ適合率
マクロ適合率は、AIの分類した結果が、正解である割合の平均を示しています。
実際の値と一致している割合を表す「正確性」に関する評価指標です。
例えば機器の故障を予測する場合、故障と予測した機器が、実際に故障した機器であった割合を示しています。
誤認識・誤検知をなるべく抑えたいときによく使われる指標です。例えば、迷惑メール判定課題では正しく迷惑メールを認識できることは大事ですが、厳しく判定してしまうことで重要なメールの見逃しが発生することも問題が生じます。そのため、迷惑メールではないものの誤検知をなるべく抑える必要が出てきます。
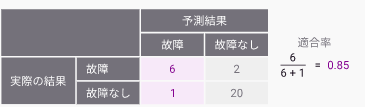

②マクロ再現率
マクロ再現率は、実際に正解であるものをAIが正解と予測できた割合の平均を示しています。
正解をどれだけ予測できたのかを表す「網羅性」に関する評価指標です。
例えば機器の故障を予測する場合、実際に故障した機器を、正しく故障と予測できた割合を示しています。
見逃しをなるべく抑えたいときによく使われる指標です。例えば、システムの障害や異常検知課題などの場合です。機械の故障が生じると、事故や損害を発生するリスクがあるため、このような課題ではなるべく見逃しを抑える必要があります。
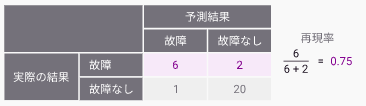

③全体正解率
全体正解率は、予測結果が正解である割合を示しています。
例えば機器の故障を予測する場合、故障したものを故障したと予測し、故障しなかったものを故障しなかったと予測できた割合を示しています。
すべてのクラスが同じように重要であるときによく使われる指標です。例えば、猫と犬の分類課題など、各カテゴリのサンプル数に極端な偏りがない場合に有効です。

④平均正解率
平均正解率は、列ごとの予測が正解である割合を平均した値です。
例えば機器を故障、故障していない、故障しかけに分類する場合、故障しているものを故障と予測できた割合を計算し、同様に故障していない・故障しかけの場合も計算し、その割合の平均がこの値になります。
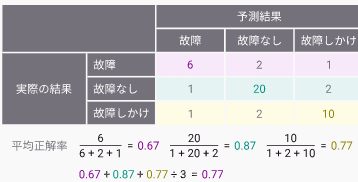

⑤マクロF値
マクロF値は、適合率と再現率の調和平均です。マクロF値は最大で1になります。
例えば機器の故障を予測する際に、全て故障と答えるAIを作成した場合、再現率は極端に高くなりますが、適合率は低くなり、F値も小さくなります。
適合率と再現率が同等に重要なときによく用いられる指標です。適合率と再現率をバランスよく考慮して評価したいときに使われます。
⑥AIの精度のグラフ(混同行列)
実際データセットの中の値と予測値の分類表です。
先に記載した再現率や適合率、正解率の説明の下にある画像も混同行列で、それらの精度はこの混同行列をわかりやすく表した指標になります。
①~④のどの値も、95%を超えており、精度は高いといえます。
さらに、上のメニューから「テキストマイニング」をクリックし、結果を見てみましょう。
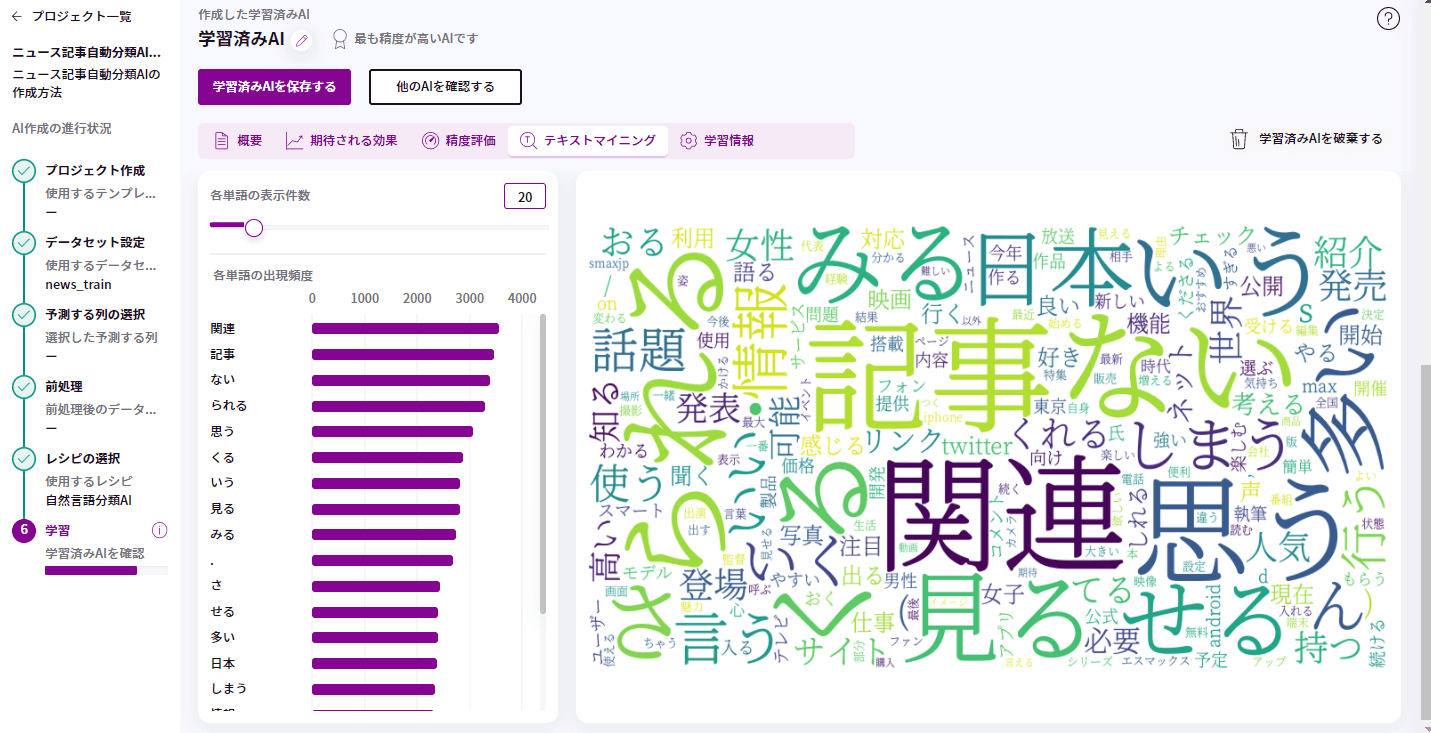

テキストマイニングとは、学習した文章をフレーズや単語に分解して詳細に解析し、有用な情報を抽出する分析手法のことをいいます。
①各単語の表示件数と出現頻度
学習した文章の中にある単語やフレーズの、登場回数を表示しています。また、各単語の表示件数を調整することで、下部にある各単語の出現頻度の表示内容の調整を行う事が出来ます。
②ワードクラウド
単語の表示頻度によって表現の変わるワードクラウドが表示されます。
①をみると、「関連」、「記事」、「ない」などの単語が上位3位を占めており、②をみると、「関連」、「記事」、「ない」の単語が大きく表示されていて、視覚的にもわかりやすくなっています。
ひと通り学習結果が確認出来たら、左上の「学習済みAIを保存する」ボタンを押して保存しておきましょう。
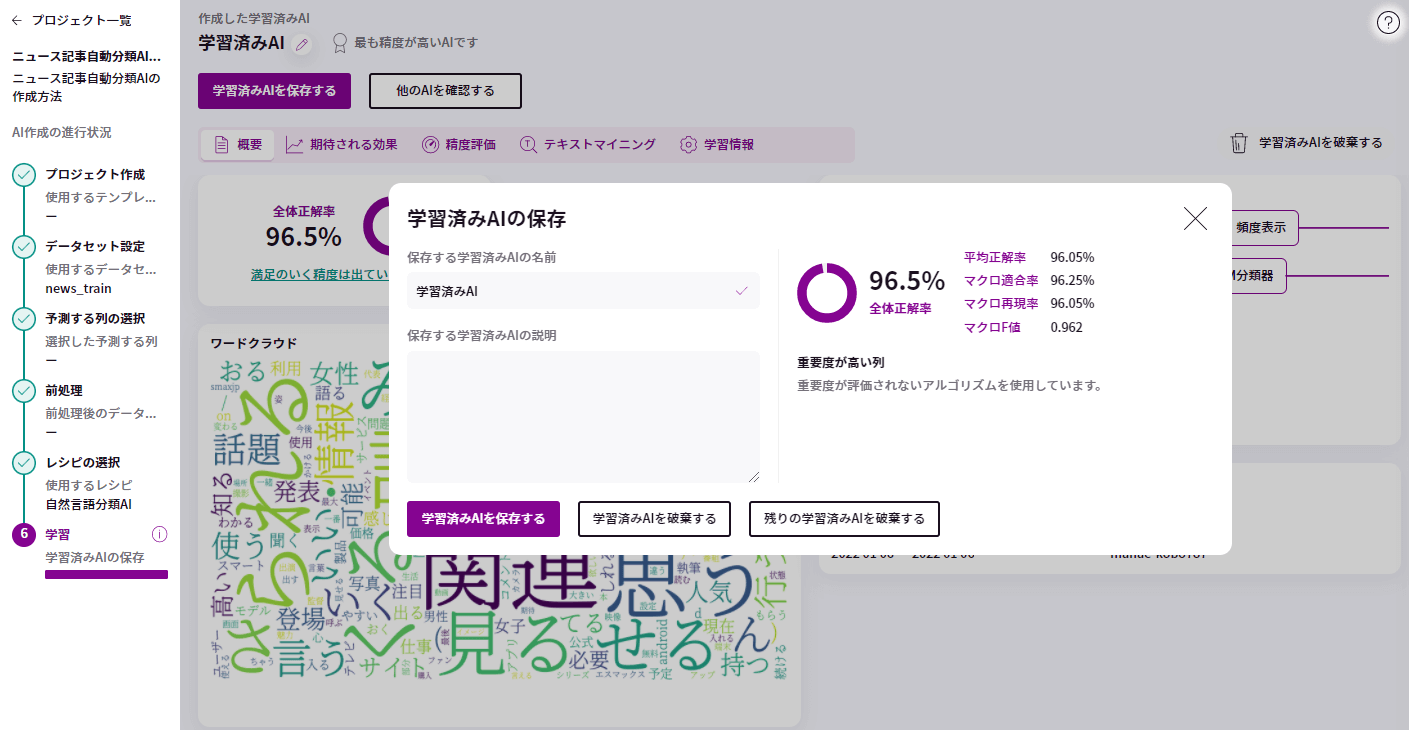

保存が完了するとポップアップが表示されるので、「このAIを使って推論をする」をクリックしましょう。
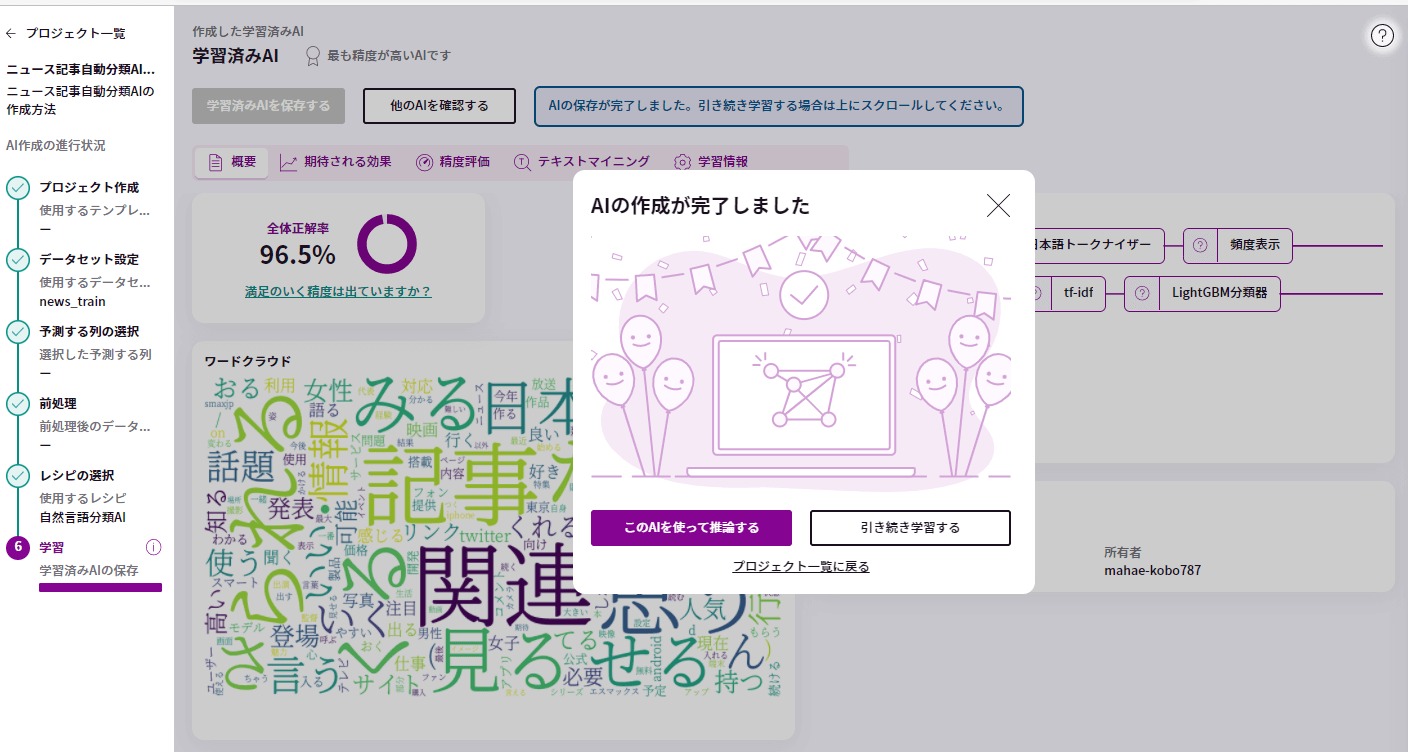

8. 推論
先程作成したAIを使ってさっそく予測をしていきましょう。また、AIが予測を行うことを「推論」といいます。
推論用のデータは、先ほどデータ管理にアップロードする用のデータを作っていた際、事前に18個のニュース記事を抜いておきました。
これらのデータは、学習にもテストにも使ってない新しいニュース記事ということになります。これらのニュース記事がどのカテゴリの記事なのか、これから予測してみたいと思います。
フォルダを一つ作成し、その中にtextsという名前のフォルダを作り、その中に18個のニュース記事を入れ、zipファイルに圧縮します。これが予測対象のzipファイルになります。
それでは、推論用のデータセットをアップロードします。
※ここでは、学習を完了して直接推論に進んでいますが、一旦学習を終えており、プロジェクトからあらためて推論を開始する場合は、学習済みAIの選択をしてから、データセットをアップロードしてください。

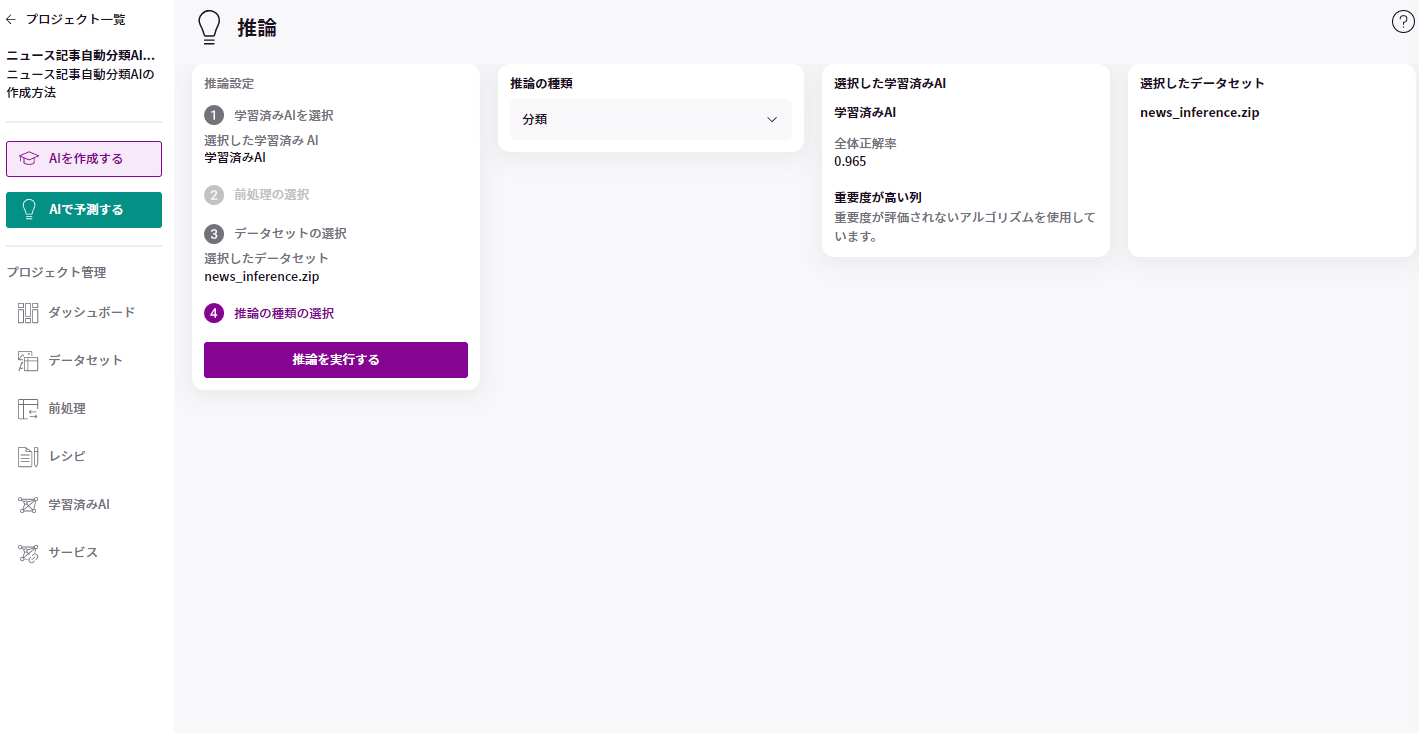
推論の種類は「分類」を選び、「推論を実行する」をクリックしましょう。

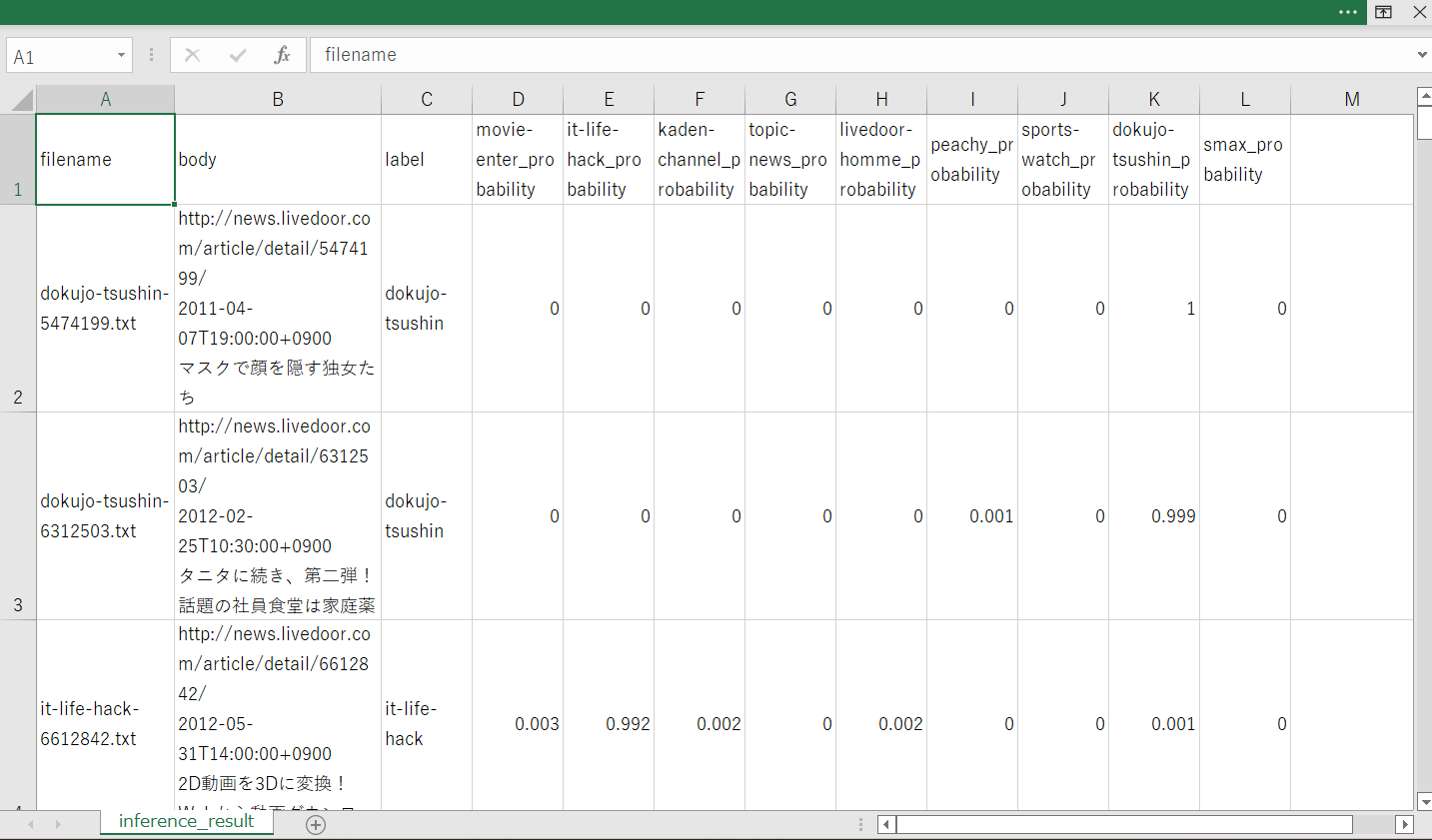
推論結果が表示されました。
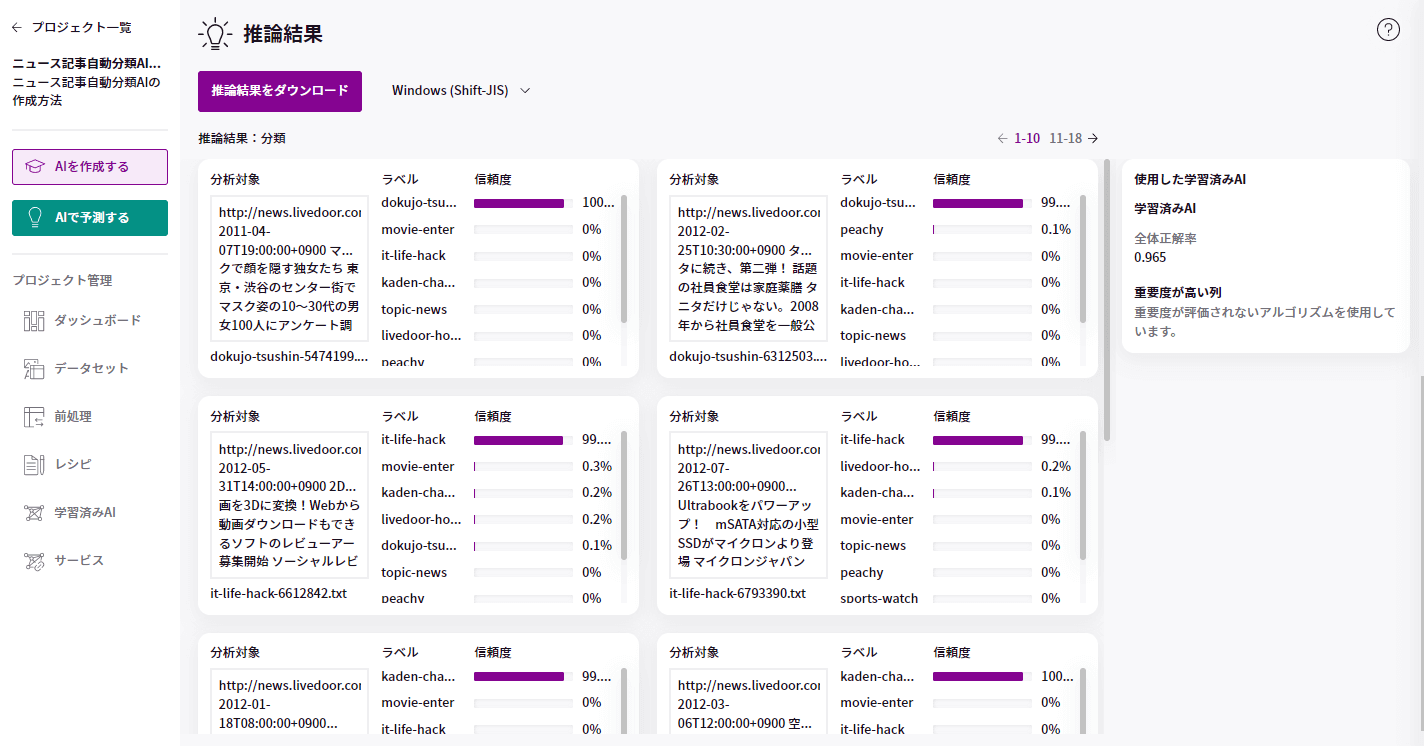

それぞれのボックスの左側には、分析対象のテキストが表示されます。このテキストは先程準備した推論用データに入っているテキストです。
ボックスの右側には、学習済みAIを元に推論した結果が表示されました。信頼度が最も高く表示されているものが、そのテキストが属するニュースのカテゴリーになります。
テキスト文の部分をクリックすると、拡大表示されます。
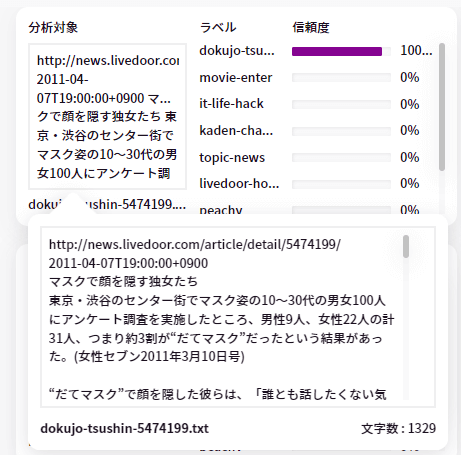

この結果は、左上の「推論結果をダウンロード」をクリックすると、csvファイルとしてダウンロードすることができます。

9. まとめ
この記事では、ノンプログラミングで自然言語分類の手法を使って、テキストデータからニュース記事を自動分類するAIを作成しました。MatrixFlowで自然言語を分類するAIを作成することで、例えば、報告書や論文を分析・分類したり、問い合わせ内容を自動で分類したり、SNSやコメントのレビュー分析によるマーケティングへの応用など、さまざまな文章を自動で分析・分類し、活用することができます。
ぜひMatrixFlowを使って自然言語を分類するAIをみなさんも作ってみませんか?
MatrixFlowは、ドラッグ&ドロップだけで前処理も含めた機械学習・深層学習が可能で、学習データや学習済みモデルの管理機能、サービスに組み込むためのAPIの作成機能も搭載しており、ウェブから推論するだけではなく、外部のアプリからAIを利用できます。リアルタイムで推論したいという用途にも使えますので、AIの導入検討で生じる、あらゆる悩みを解決します。
実際に操作する際に役立つマニュアルや、AIの作り方や推論結果の見方や精度の高め方などAIコンサルタントに相談できるサポート体制もありますので安心です。
MatrixFlowのご検討、お見積りなど、お気軽にご相談ください。
お問い合わせは以下からお願いいたします。
マニュアル http://www.matrixflow.net/manual/top/
問い合わせ http://www.matrixflow.net/contact/