

こんにちは。MatrixFlow広報部の中野です!
今回はMatrixFlowを使って子宮頸がんのリスクになる要因を分析したいと思います。
❖データの用意❖
今回使うデータは、858人の患者の人口統計情報、習慣、および過去の医療記録となります。以下のサイトからcsvデータをダウンロードします。
『Cervical cancer (Risk Factors) Data Set』
https://archive.ics.uci.edu/ml/datasets/Cervical+cancer+%28Risk+Factors%29
ダウンロードしたファイルのデータ内容を見てみましょう!
このようなデータが入っています。
年齢
性的パートナーの数
最初の性交(年齢)
妊娠の数
喫煙の有無
喫煙年数
喫煙(パック/年)
ホルモン避妊薬
ホルモン避妊薬(年)
IUD(子宮内避妊器具)使用
IUD(子宮内避妊器具)使用年数
STD(性感染症)
STD(数値)
性感染症:コンジローマ症
性感染症:頸椎腫症
性感染症:膣コンジローマ症
性感染症:外陰部会陰部顆状突起症
性感染症:梅毒
性感染症:骨盤内炎症性疾患
STD:性器ヘルペス
STD:伝染性軟腫症
STD:AIDS
STD:HIV
性感染症:B型肝炎
STD:HPV
STD:診断の数
STD:最初の診断からの時間
STD:最後の診断からの時間
Dx:Cancer
Dx:CIN
Dx:HPV
Dx
Hinselmann:ターゲット変数
シラー:ターゲット変数
細胞学:ターゲット変数
生検:ターゲット変数
年齢や生活習慣、その他の検査結果など、様々なデータが入っています。
このデータセットを使って、子宮頸がんの要因分析AIをつくっていきたいと思います。
では、MatrixFlowにアクセスして、“AI” で分析してみましょう!
◆MatrixFlowの操作◆
プロジェクト作成
MatrixFlowにログインして、はじめに、プロジェクトを作成します。
プロジェクト一覧から「新規プロジェクトを作成する」をクリックします。
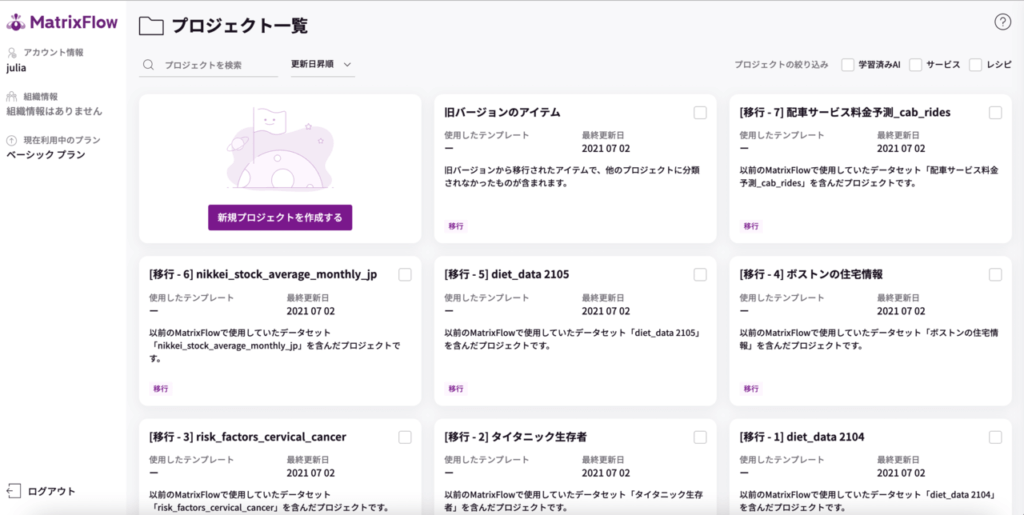
「テンプレートを使用してAIを構築する」または「自分でAIを構築する」のどちらかを選択します。今回は、「自分でAIを構築する」を選択。
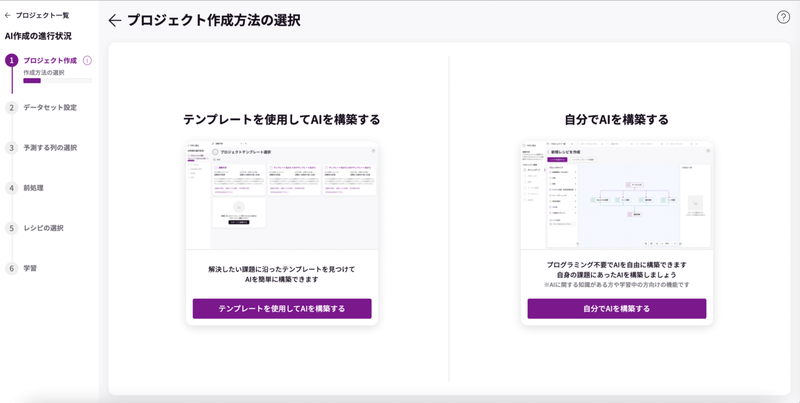


プロジェクト名とプロジェクトの説明を入れて作成します。
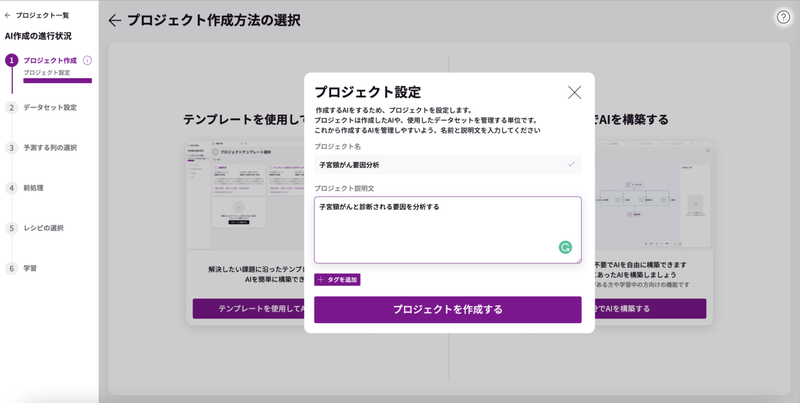
データアップロード
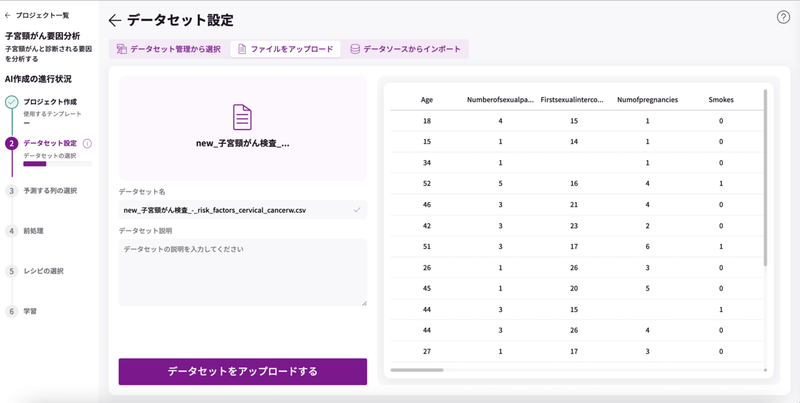
データセットの設定を行います。使用するデータを設定するには、3つの方法がありますが、今回は「ファイルをアップロード」します。
上記で用意したcsvデータを所定の場所にドラッグ&ドロップします。
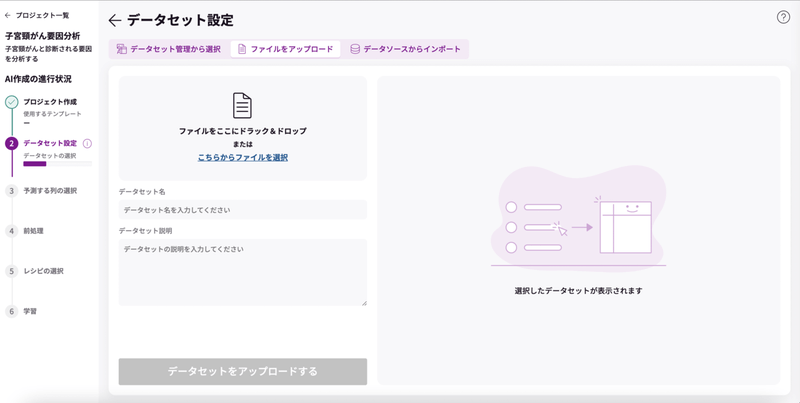
データを取り込めたようですね。ファイルの情報が表示されたら、名前と説明を入力して「データセットをアップロードする」をクリックしましょう。
ーーーーー
注意:
今回、アップロード前にデータを少し加工しました。
作業を進めていくとエラーが出て原因を探るとデータに問題がありました。以下2点を実施しました。
①数値以外の値を削除
→ 「?」が数カ所入っていたが、データは有無(1 or 0)または回数などで構成されていたので、「?」は不要とした。
②半角スペースの削除
→①を行った上でファイルをアップロードしたが、エラーが出てしまい、データをよく見ると、欠損値となっていたところに半角スペースが入っていた。
→スペースがあることで欠損値と認識されず、また数値としても認識されないためエラーが起きていた。
これを消すことで、エラーを解消した。
ーーーーー
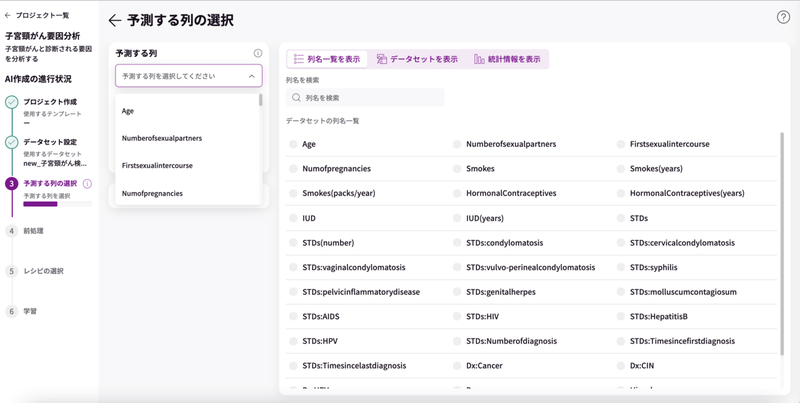
予測する列の選択
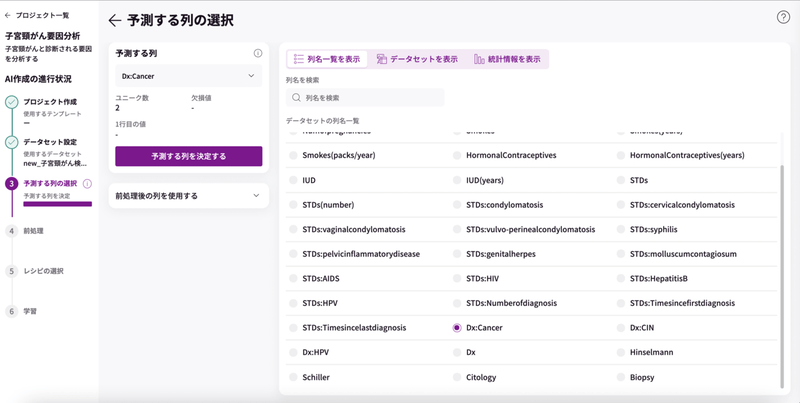
今回は、子宮頸がんの要因を分析したいので、がんと診断されたかどうかを記した項目「Dx:Cancer」を選択し、「予測する列を決定する」をクリックします。
データ前処理
前処理のページへ飛びました。
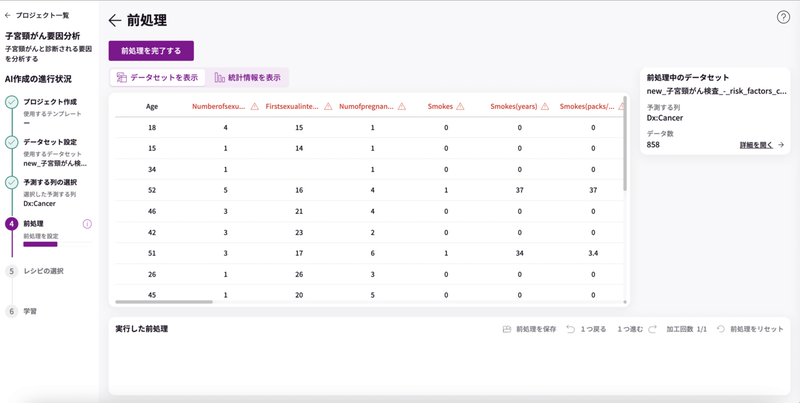
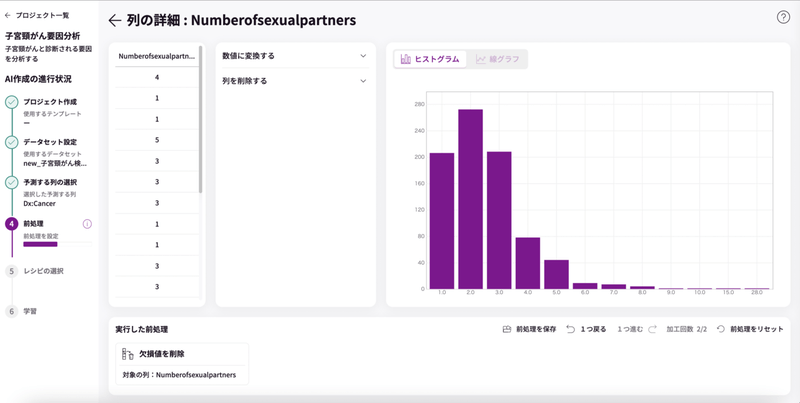
データの詳細を見てみると、「列の詳細」のところで赤文字になっているのが確認できます。
赤文字にポイントを合わせるとグラフマークが表示されるのでクリックしてみましょう。
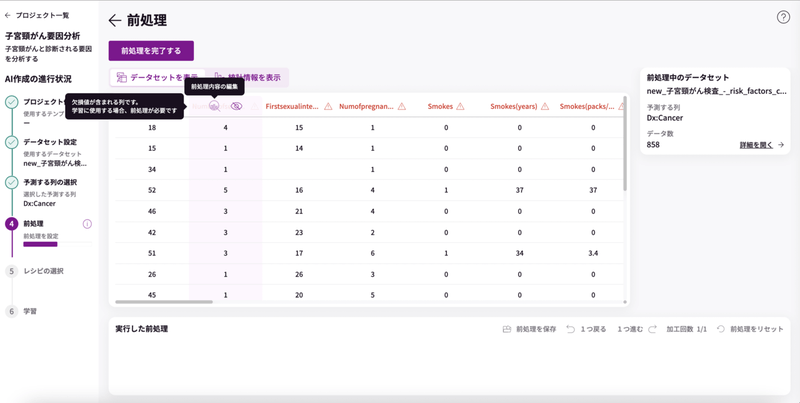
列の詳細が表示されます。
「欠損値を変換する」が赤文字になっているので、中身を見てみましょう。
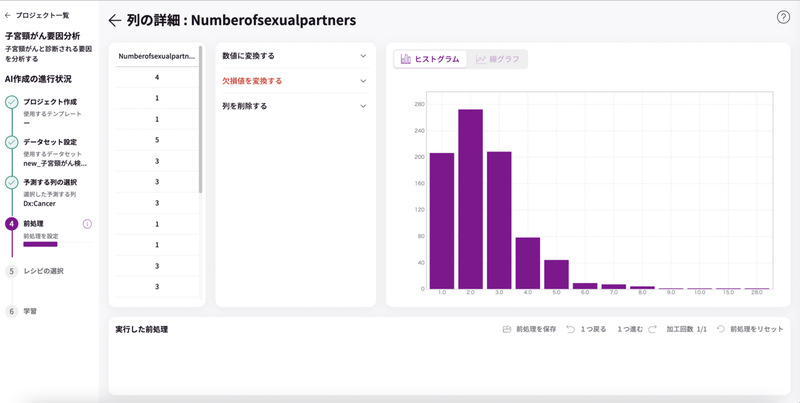
「欠損値の数:26」となっています。
これは、列にデータが全て埋まっていなくて空欄のセルが存在していることを意味します。この空欄のことを「欠損値」と呼びます。
機械学習では欠損値があるとうまく学習できない場合があるので、欠損値を消す必要があります。
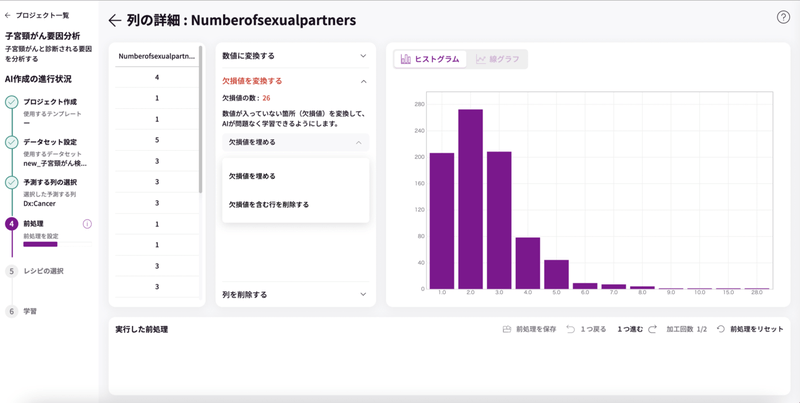
「欠損値を変換する」から「欠損値を埋める」を開くと「欠損値を含む行を削除する」と表示され、クリックすると削除を実行するボタンが現れますので、クリックして実行します。
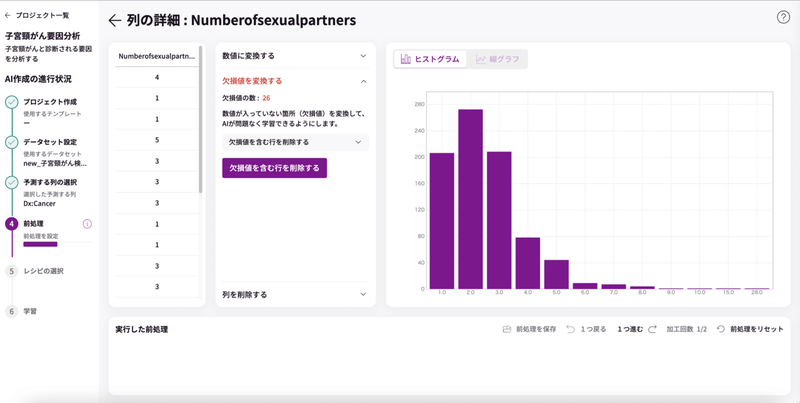
完了すると、欠損値のエラー表示がなくりました。
左上の「左矢印」をクリックして、他の赤文字の項目も同様の処理を行います。
注意:今回は、「STD:最初の診断からの時間」とSTD:「最後の診断からの時間」については欠損値の数が600を超えるため、データ量が少なくなってまうので、行の削除はせずに進めます。
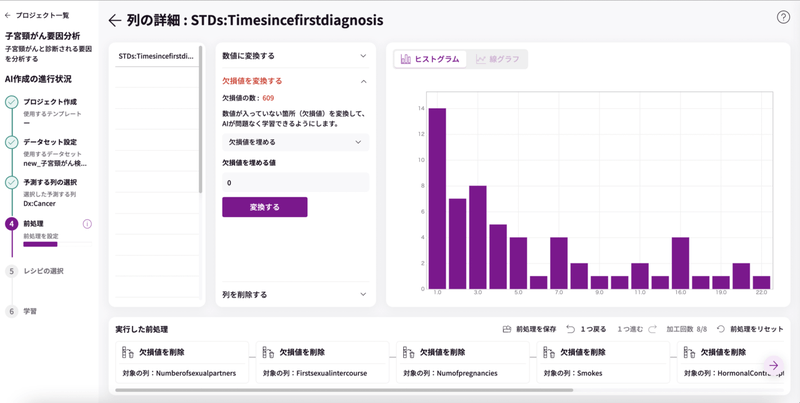
このように機械学習をする前にデータを加工することを「前処理」と言います。
全ての処理が完了したら、左上の「前処理を完了する」をクリックします。
「名前」と「説明」を入力して、保存します。
レシピ
データの準備ができたので、AIの設計図「レシピ」をつくっていきましょう!
レシピ管理のページで、新規作成ボタンをクリックします。
「ブロックタイプ」からAIで何をするのかを選びます。
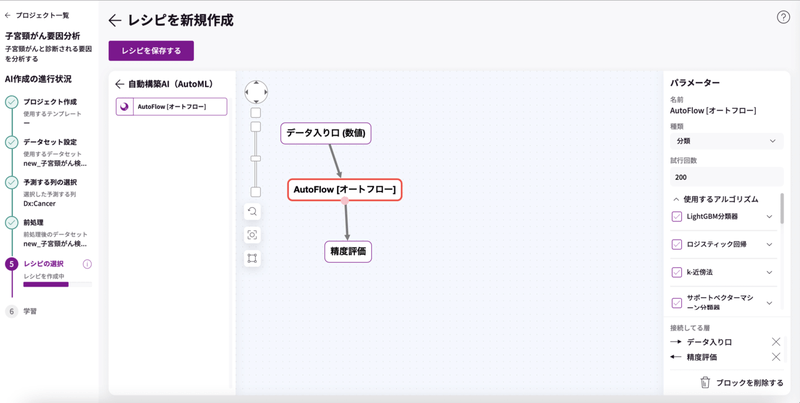
今回は自動構築AIのAutoMLから「AutoFlow(オートフロー)」を使います。
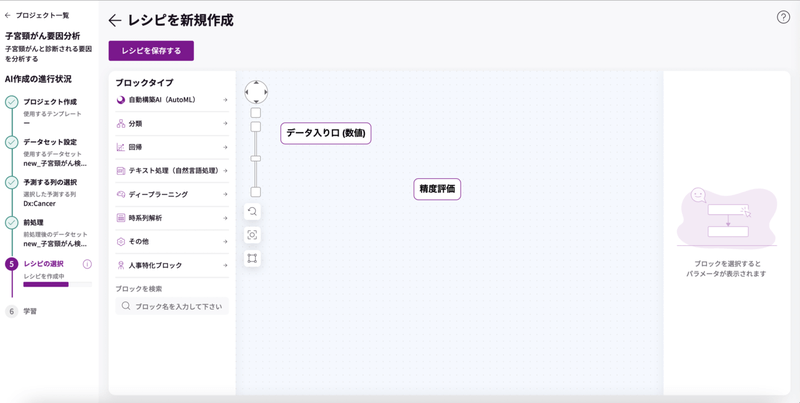
「AutoFlow」を設置エリアにドラッグアンドドロップして、「データ入り口」ブロックと「精度評価」ブロックに繋げます。
ブロックにポインターを合わせるとピンクの丸ポチが出てきますので、繋ぎたいブロックまで引っ張ります。
繋がったら「名前」と「説明」を入力して保存します。これでレシピの用意は完了です!
AIの学習
AIの学習ページで、学習に使用する列(項目)を選択します。
今回は、全て選択します。「列名」にチェックを入れると全て選択されます。
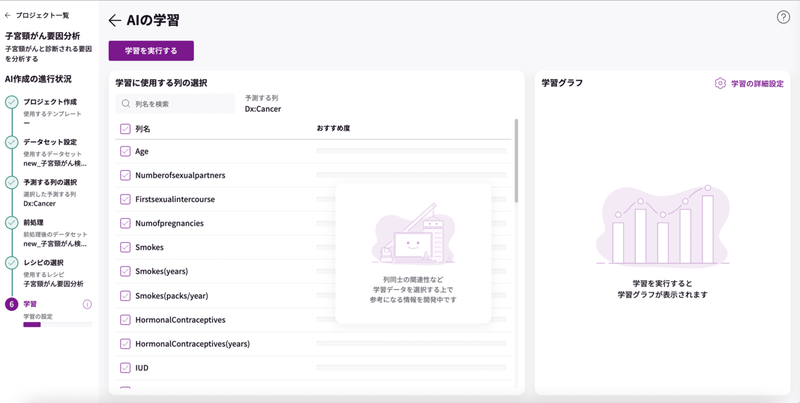
「学習を実行する」をクリックすると学習が始まります。
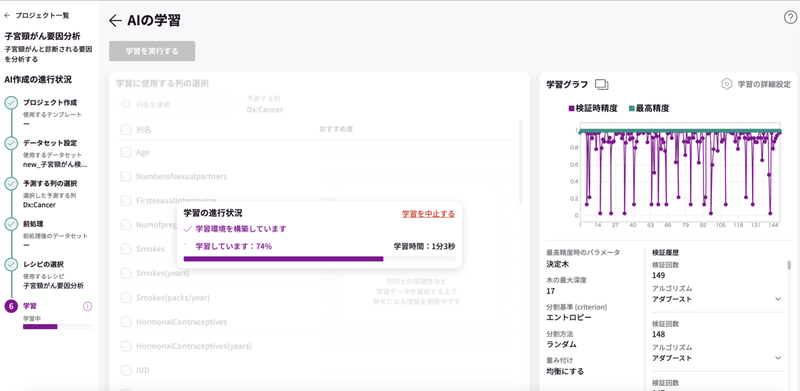

数分で結果が表示されました。
子宮頸がんは、HPV(ヒトパピローマウイルス)に感染が発症に大きく影響していることがわかりました。
重要度は学習にどの列が寄与しているかを可視化する機能です。
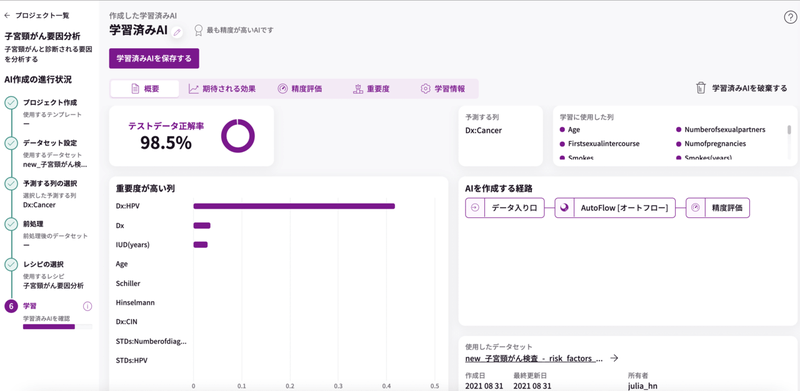
AIの学習結果の詳細を見てみる
今回は、この結果がどのように導かれたのかも見ていきたいと思います。
「学習情報」のタブを開いてみましょう。
右側に学習結果の詳細が表示されています。最高精度時のパラメータ アルゴリズムが「決定木」となっています。
右側に使用したアルゴリズムが表示されていますが、レシピで「AutoFlow」を使用したので、たくさんのアルゴリズムで検証されました。
その中で「決定木」の精度が高かったこということになります。
続いて、「テストデータ / 学習データ」の数字をみてみましょう。これは、601のデータからランダムに67のデータを検証(テスト)したということになります。
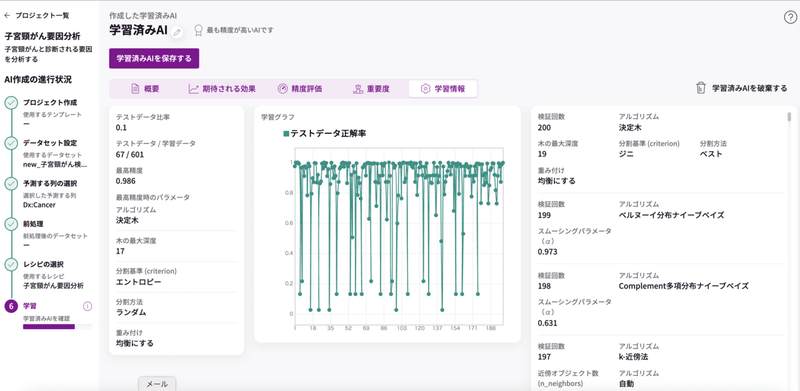
この数字についてさらに深掘りしてみます。
精度評価の「AIの精度のグラフ」の数字を見てみましょう。
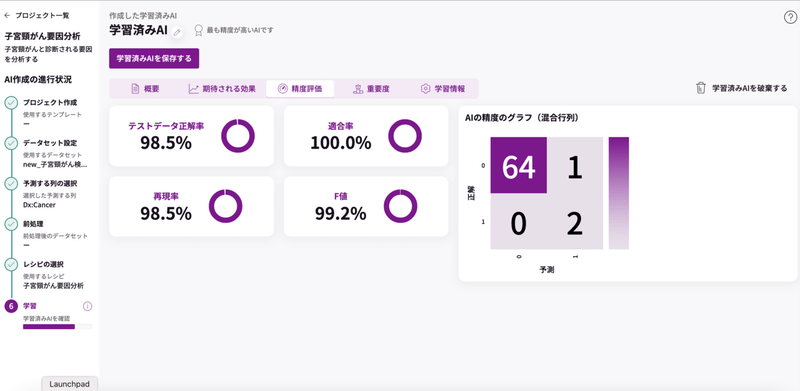
「64」「1」「2」「0」を足すと「67」になりますね。
このグラフがテストデータ「67」の内訳になっています。
縦軸横軸の「1」は子宮頸がん患者を意味しているので、
この結果から言えることは、
「64」が、AIに「子宮頸がんではない」と予測されて、実際に「子宮頸がんではなかった」
「2」が、AIに「子宮頸がんだ」と予測されて、実際に「子宮頸がんだった」
「1」が、AIに「子宮頸がんだ」と予測されたが、実際には「子宮頸がんではなかった」
と読み取れます。
この「1」は縦軸0、横軸1の交わるところに位置しています。疑わしかったが子宮頸がんではなかったということですね。
テストデータの正解率を見ると、98.5%。「1」の割合を見ると1.49%です。計算が合いますね。AIはもちろん100%の正解を導き出すことはできません。ですが、人が手動で分析をしたらこのような正解率は出せないのではないでしょうか。
このように、データがあればMatrixFrowでの操作は簡単です。
この学習データを使って、子宮頸がんになる可能性を予測することで多くの人の予防につながると思います。