このセクションの他の記事
ClusterFlowとは
ClusterFlowは、クラスタリングが行えます。クラスタリングでは、データは複数の特徴量(属性)を持つベクトルとして表現されます。
データの次元とは、各データポイントが持つ特徴量の数を指します。次元圧縮(次元削減)とは、高次元のデータを情報をなるべく保持しながら低次元に変換する手法です。クラスタリング前に次元圧縮を行うことで、計算の負担を軽減し、より適切なクラスタ構造を見つけることができます。
ClusterFlowを使ったレシピは、プロジェクトテンプレート[顧客分類・キャンペーン分析(クラスタリング)]にセットされています。
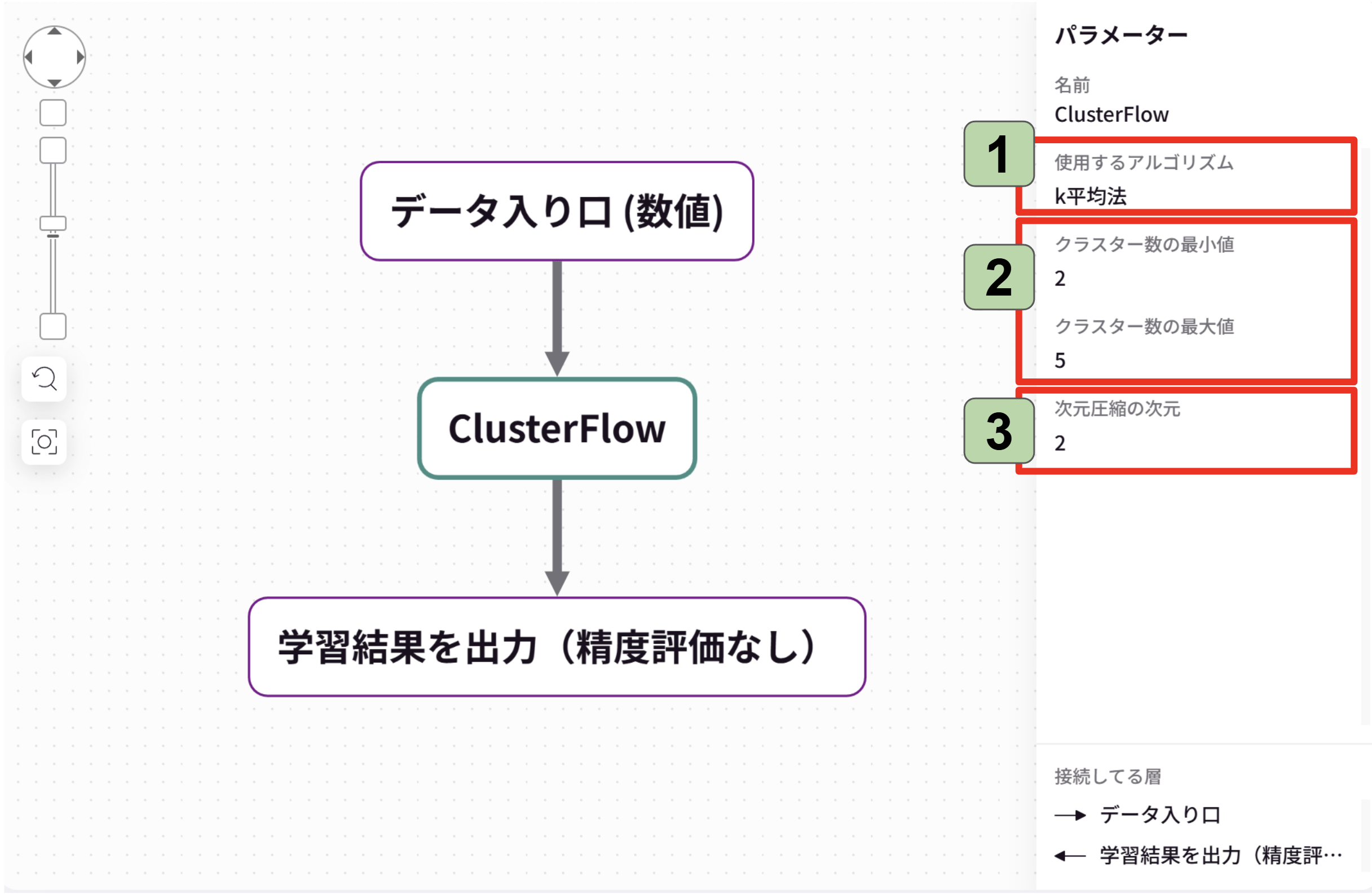
■特徴
データの特徴から分類分け、クラスタリングを行うことが可能です。
■パラメータについて
1.使用するアルゴリズムを変更します。
2.クラスター数の最小値と最大値を設定します。学習後に表示されるクラスの最大値と最小値が設定できます。
3.次元数を設定します。(クラスの他に、次元で表示することが可能になります)
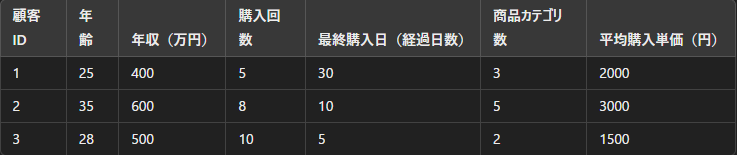
上記画像の様に、あるECサイトの顧客データが以下の6つの特徴量(次元)を持っているとします。
このデータは 6次元(年齢/年収(万円)/購入回数/最終購入日(経過日数)/商品カテゴリ数/平均購入単価(円)) です。

これを次元圧縮をして6つの特徴を「よりシンプルな3つの要素(購買行動・収入・価格志向)」に圧縮することで、データを理解しやすくなり、クラスタリングもしやすくなります。
(一例)3次元に変換した場合。